Python Tutorial Teil 3 - Bibliotheken für Machine Learning
Teil 3: Machine Learning dieses kompakten Python-Tutorials gibt eine Übersicht über die wichtigsten Bibliotheken für Datenanalyse und Maschinelles Lernen. Zunächst werden die Pakete NumPy, Matplotlib und Pandas vorgestellt, die für Datenvorbereitung und -Visualisierung verwendet werden. Anschließend wird die Verwendung der Machine Learning-Bibliothek Scikit-Learn am Beispiel einer Klassifikation für die Vorhersage von Ausfällen erklärt. Schließlich wird die Erstellung eines Künstlichen Neuronalen Netzwerkes für die Bilderkennung mit Hilfe der Bibliotheken Keras und Tensorflow illustriert.
Motivation
Machine Learning ist ein Teilgebiet der Künstlichen Intelligenz, das es Systemen ermöglicht, auf Basis von Trainingsdaten automatisch zu lernen und hinzuzulernen. Machine Learning-Anwendungen wie z.B. Bildbearbeitung oder Ausfall-Vorhersage werden häufig mit Python entwickelt. Python hat umfangreiche und kostenlose Bibliotheken für Datenanalyse und Machine Learning, die alle relevanten Algorithmen des Machine Learning abbilden: Entscheidungsbaum-Verfahren, Clusteranalysen, Künstliche Neuronale Netzwerke. Die üblichen Schritte der Machine Learning-Pipeline, wie Datenvorbereitung, Modellauswahl, Modell trainieren, Modell validieren werden durch aufeinander abgestimmte Bibliotheken umgesetzt.
1 Python-Pakete für Datenanalyse
Zu den wichtigsten Python-Bibliotheken für Datenanalyse und Datenvisualisierung gehören:
- NumPy - Funktionen für das Erstellen und Bearbeiten mehrdimensionaler Arrays und Zufallszahlen
- Matplotlib - Funktionen für Datenvisualisierung und Diagramme
- Pandas - Funktionen für das Erstellen und Bearbeiten tabellenartiger Daten: Series, DataFrames
1-1 NumPy
NumPy ist eine Python-Bibliothek für Datenauswertung und bietet Unterstützung für die Erzeugung, Umformung und statistische Auswertung von Arrays und Zufallszahlen. Mit NumPy können Arrays erstellt, mit Default-Werten initialisiert und extrahiert werden, man kann elementweise Operationen an Arrays durchführen, Elemente sortieren, suchen, zählen und Array-Statistiken berechnen. NumPy bietet auch mathematische Konstanten und Funktionen (pi, sin, cos ...).
NumPy verwenden: 1D und 2D-Arrays
Im folgenden Beispiel wird die Erzeugung von 1D und 2D-Arrays gezeigt.
Zunächst werden zwei eindimensionale NumPy-Arrays x1 und x2 mit jeweils vier Elementen erstellt:
x1 aus einer Liste über den Array-Konstruktor np.array(), x2 als Zahlenfolge (Start: 1, Ende: 8, Schrittweite 2) über die Funktion arange().
Mit Hilfe des Ausdrucks sum = x1 + x2 wird die elementweise Summe der beiden NumPy-Arrays berechnet.
Die elementweise Summe zweier NumPy-Arrays kann alternativ auch mit sum = np.add(x1, x2) berechnet werden.
Danach werden zwei zweidimensionale Arrays a1 und a2 erstellt: eine 2x2 Matrix a1 mit den Elementen 1, 2, 3, 4,
und a2 als 2x2 Einheitsmatrix mit Hilfe der Funktion eye().
Für die beiden 2D-Arrays wird schließlich mittels prod = a1 * a2 das elementweise Produkt berechnet.
Ausgabe: NumPy verwendenimport numpy as np# Eindimensionale Arraysx1 = np.array([1, 2, 3, 4])x2 = np.arange(1, 8, 2) # 1, 3, 5, 7sum = x1 + x2 # Elementweise Summeprint('x1:', x1, '\nx2:', x2, '\nsum:', sum)# Zweidimensionale Arraysa1 = np.array([[1, 2], [3, 4]], )a2 = np.eye((2))prod = a1 * a2 # Elementweises Produktprint('a1:\n', a1, '\na2:\n', a2, '\nprod:\n', prod)

Häufig verwendete Funktionen für die Umformung von NumPy-Arrays sind: np.reshape() - ändere die Dimensionen des Arrays, np.transpose() - transponiere Array.
NumPy Arrays vs. Python Listen
Was ist also der Unterschied zwischen NumPy Arrays und Listen der Python Standardbibliothek?
NumPy-Arrays haben eine feste Größe, enthalten Elemente desselben Datentyps und unterstützen effizient elementweise Operationen und
eine Vielzahl statistischer Funktionen. Sie werden daher bevorzugt im Umfeld der Datenanalyse eingesetzt.
Im folgenden Beispiel werden verschiedene Arten der Summenbildung bzw. Addition gezeigt: der "+"-Operator ist jeweils
abhängig von dem Datentyp der Operanden mit einer anderen Funktionalität belegt.
- Addiert man zwei Python-Listen, so ist das Ergebnis eine neue Liste, in der die Elemente aneinandergefügt wurden.
- Addiert man zwei NumPy-Arrays, so ist das Ergebnis ein neues Array, das die elementweise addierten Elemente enthält.
Die elementweise Addition kann auch mit Python Listen durchgeführt werden, jedoch komplizierter, dann muss eine Schleife oder die
sogenannte List Comprehension verwendet werden, wie im Beispiel unten.
import numpy as np# Zwei Python Listenlist1 = [1, 2, 3, 4]list2 = [5, 6, 7, 8]# Konvertiert in NumPy Arraysarr1 = np.array(list1) # NumPy Array [1 2 3 4]arr2 = np.array(list2) # NumPy Array [5 6 7 8]# Verschiedene Arten der Addition / Summenbildungprint("Addiere Python Listen: Aneinanderfügen!")sum = list1 + list2print(sum) # [1, 2, 3, 4, 5, 6, 7, 8]print("Addiere NumPy Arrays: Elementweise Summe!")sum = arr1 + arr2print(sum) # [6 8 10 12]print("Elementweise Summe für Listen, ohne NumPy:")sum = [x + y for x, y in zip(list1, list2)]print(sum) # [6 8 10 12]
Eine Konvertierung von und zu Python-Listen ist mittels Konvertierungs-Funktionen problemlos möglich:
# NumPy Array erstellen arr = np.array([1, 2, 3, 4]) # NumPy Array in Liste konvertieren list = arr.tolist()
1-2 Matplotlib
Matplotlib ist eine Python-Bibliothek für Datenvisualisierung, die über das Paket pyplot das Erstellen von Diagrammen unterschiedlichster Art unterstützt: Linien-, Punkte-, Balkendiagramme, ein- und zweidimensonal, statisch oder interaktiv. Die wichtigsten Befehle zum Plotten sind plot für eindimensionale und surf für mehrdimensionale Diagramme. Der plot-Befehl erhält als Parameter die x- und y-Koordinaten der darzustellenden Daten, und optional einen String mit Formatierungsangaben. Weiterhin stehen viele Optionen zum Hinzufügen von Beschriftungen, Titeln, Legenden etc. zur Verfügung.
Python-Code: Matplotlib verwendenAusgabe: Datenvisualisierung mit Matplotlibimport numpy as npimport matplotlib.pyplot as pltx = np.linspace(0,10,40) # x-Wertey1 = np.sin(x);y2 = np.cos(x); # y-Wertefig = plt.figure(figsize=[6, 3]) # Diagrammfenster mit festgelegter Größeplt.plot(x, y1,'r*', label='sin'); # Plot der Sinus-Funktionplt.plot(x, y2,'b+', label='cos'); # Plot der Cosinus-Funktionplt.title('Sinus und Cosinus-Funktion');plt.grid(True)plt.legend(loc="upper center")plt.xlabel('x');plt.ylabel('y');
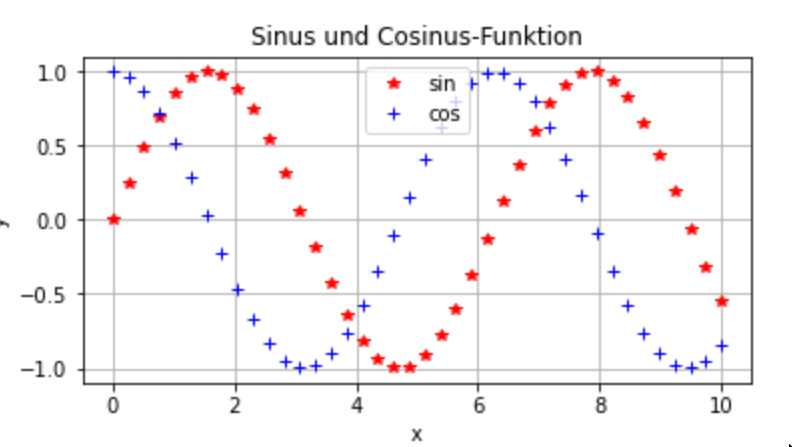
1-3 Pandas
Pandas ist eine Python-Bibliothek, die spezielle Datenstrukturen - Series und DataFrames - für den Zugriff auf Excel-ähnliche beschriftete Datentabellen anbietet, sowie viele Funktionen, mit deren Hilfe die Daten erstellt, bearbeitet und visualisiert werden können. In der Datenanalyse spielt Pandas eine zentrale Rolle, da damit große Excel- und csv-Dateien in den Arbeitsspeicher des Programms geladen werden, mit dem Ziel, die Daten anschließend zu analysieren und visualisieren. Pandas-Funktionen wie iloc(), loc(), resample() werden verwendet, um Zeilen / Spalten / Zellen auszuwählen und Daten zu gruppieren und aggregieren.
Beispiel 1: Pandas verwenden
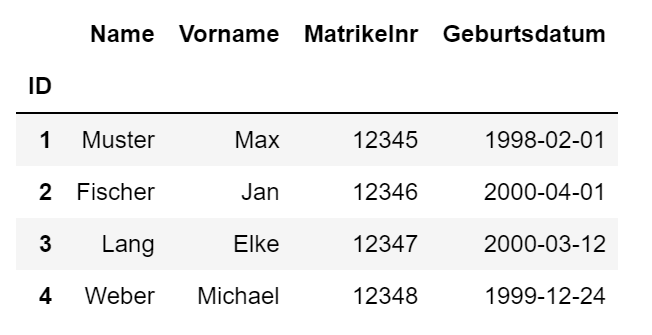
In diesem Beispiel werden mit Hilfe der Pandas-Funktion read_excel()
Daten aus einer Excelmappe in ein DataFrame eingelesen und mittels to_csv() in eine csv-Datei geschrieben.
Die Excel-Datei studenten.xslx können Sie hier herunterladen, danach einfach der Variablen file
den geänderten Dateinamen inkl. Pfadangabe übergeben.
Datei studenten.xlsx herunterladen
import pandas as pd# Daten aus studenten.xlsx einlesen, erste Spalte enthält den Indexfile = 'https://www.elab2go.de/demo-py1/studenten.xlsx'df = pd.read_excel(file, index_col=0, parse_dates=True)# Daten in die csv-Datei schreiben, mit angegebenem Trennzeichendf.to_csv('studenten.csv', index=True, sep = ';')# DataFrame df ausgebendf
Ausgabe
Das DateFrame df wird einfach durch Angabe des Namens formatiert ausgegeben.
Zeile 4: Die Angabe index_col = 0 im Funktionsaufruf bewirkt, dass die erste Spalte der Excelmappe (hier: die Spalte ID) als
Index-Spalte festgelegt wird, d.h. sie wird die eindeutigen Zeilenbeschriftungen enthalten.
Beispiel 2: Pandas verwenden
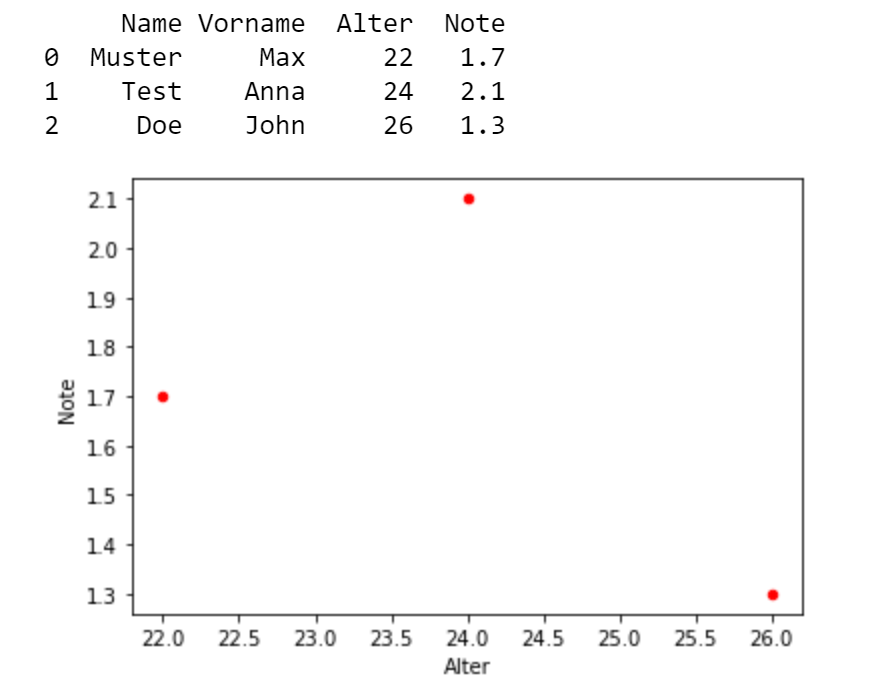
In diesem Beispiel wird ein DataFrame mit Hilfe der Funktion pd.DataFrame aus einem Dictionary gebildet,
das jedem Spalten-Namen eine Liste von Werten zuordnet,
z.B. die Spalte Name enthält die Liste der Namen Muster, Test und Doe.
Ausgabeimport pandas as pd# Erzeuge ein Dictionary (Name-Wert-Paare)studenten = {"Name": ["Muster", "Test", "Doe"],"Vorname": ["Max", "Anna", "John"],"Alter": [22, 24, 26],"Note": [1.7, 2.1, 1.3]}# Erzeuge DataFrame aus Dictionarydf = pd.DataFrame(studenten) # DataFrame aus Dictionaryprint(df)# Scatter-Plot Note vs. Alterdf.plot.scatter(x = 'Alter', y = 'Note', c='Red');
2 Python-Pakete für Machine Learning
Die Algorithmen und Verfahren des Machine Learning werden in Python durch das Paket Scikit-Learn unterstützt. Für Deep Learning im engeren Sinn, also die Verwendung leistungsfähiger Künstlicher Neuronaler Netzwerke, bietet Python gleich mehrere Programmbibliotheken, darunter PyTorch, JAX, Tensorflow und Keras. Diese Pakete bieten ähnliche Funktionalität für die Erstellung und Verwendung von Deep Learning-Modellen, sind jedoch nicht als gleichwertig zu betrachten. Keras insbesondere ist ein Paket mit Wrapper-Funktionalität, das mit jedem der drei anderen Pakete als Backend verwendet werden kann. PyTorch, JAX und Tensorflow unterscheiden sich in der internen Umsetzung der Verfahren und auch in der Verwendung der API-Funktionen.
2-1 Scikit-Learn
Scikit-Learn ist eine Python-Bibliothek für Machine Learning und bietet Unterstützung für die üblichen Schritte des Überwachten und Unüberwachten Lernens: Datenvorbereitung, Trainingsphase und Modellevaluation, ebenso leistungsstarke Algorithmen für Klassifikations-, Regressions- und Clustering-Probleme. Die Algorithmen werden unter dem Oberbegriff Schätzer bzw. Estimator zusammengefasst. Ein Estimator ist ein Objekt, das Funktionen für das Erstellen von Modellen anbietet, insbesondere eine fit-Methode, mittels deren das Modell für gegebene Daten trainiert wird.
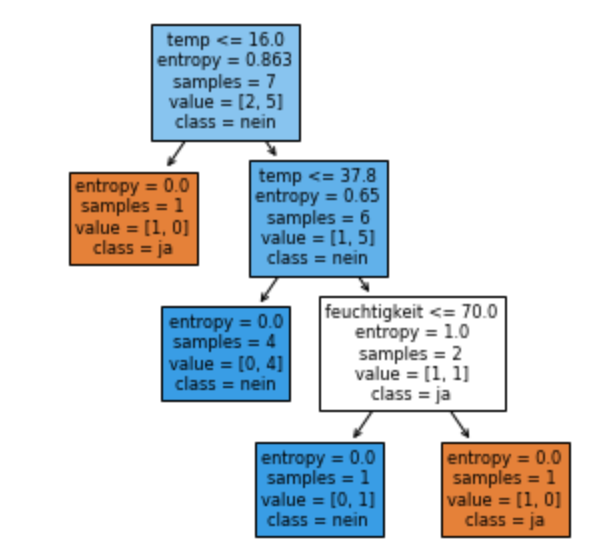
Schätzer werden unterteilt in Classificators, Regressors und Clusterers, jeweils entsprechend der Machine Learning-Kategorie, zu der sie gehören. Das abgebildete UML-Klassendiagramm zeigt einen Auszug aus der Scikit-Learn Klassenhierarchie, mit den Abhängigkeiten, Attributen und Methoden der Estimators DecisionTreeClassifier, RandomForestClassifier, DecisionRegressor, RandomForestRegressor, KMeans und AgglomerativeClustering. Aus dem Diagramm ist ersichtlich, dass alle Schätzer von der Klasse BaseEstimator abgeleitet sind, und deren fit-Methode erben, und darüber hinaus Methoden mit einheitlicher Bezeichnung wie predict() und score() haben, sowie Parameter, die den Aufbau des Modells konfigurieren.

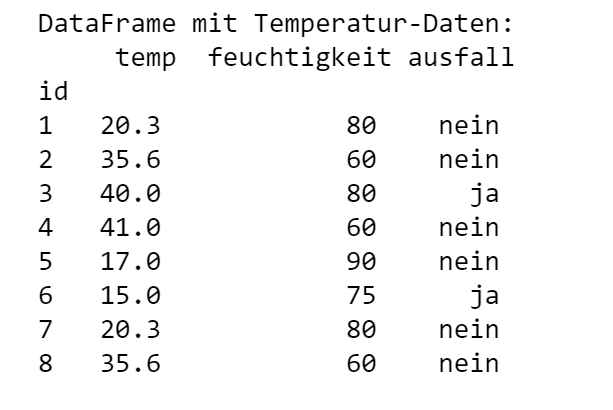
In dem folgenden Beispiel wird der vereinfachte Ablauf beim Trainieren eines Entscheidungsbaum-Modells für die Klassifikation von Ausfällen gezeigt: Einlesen der Daten mit Hilfe der Funktion read_csv, Extrahieren der Merkmale und der Zielvariablen, Aufteilen in Trainings- und Validierungsdaten mit train_test_split, Trainieren des Modells mittels fit-Funktion, Visualisierung mittels der Funktion plot_tree.
Python-Code: Scikit-Learn verwenden
Entscheidungsbaum-Modell trainieren
Ausgabeimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn import model_selection as msfrom sklearn import treedf = pd.read_csv("messungen.csv", header=0, sep = ";", index_col=0)print('DataFrame mit Temperatur-Daten:\n', df);# Extrahiere Merkmale in ein Numpy-Array xx = df.iloc[:,0:2].to_numpy()# Extrahiere Zielvariable in ein Numpy-Array yy = df[['ausfall']]y = y.values# 90% Trainingsdaten und 10% TestdatenX_train, X_test, y_train, y_test = ms.train_test_split(x, y, test_size=0.1, random_state=1)model = tree.DecisionTreeClassifier(criterion='entropy', splitter='best')# Erzeuge Entscheidungsbaummodel.fit(X_train, y_train)# Visualisiere Entscheidungsbaumfig, ax = plt.subplots(figsize=(5, 5))tree.plot_tree(model, filled=True, feature_names=df.columns[0:2], class_names=['ja','nein'])plt.show()
2-2 Keras
Keras ist ein Python-Paket, das als benutzerfreundliche Programmierschnittstelle für verschiedene Machine Learning Frameworks wie Tensorflow, PyTorch und JAX verwendet wird.
Keras bietet zum Erstellen eines neuronalen Netzwerks zwei Klassen: Sequential und Functional,
die beide die Erstellung mehrschichtiger Netzwerke unterstützen.
Die Sequential-API ermöglicht das sequentielle Zusammenzufügen von Schichten (Layer), während mit Hilfe der Functional-API
komplexere Anordnungen von Schichten erstellt werden können.
Die Schichten eines Künstlichen Neuronalen Netzwerks sind in Keras durch die Klassen der Layer-API realisiert:
Conv2D, MaxPooling2D, Flatten, Dense, LSTM etc.
Jede Layer-Klasse hat eine Gewichtsmatrix, eine Größenangabe für die Anzahl verwendeter Neuronen (units),
eine Formatbeschreibung der Eingabedaten (input_shape), eine Aktivierungsfunktion (activation), und eine Reihe weiterer Parameter,
die die Gestaltung der Schicht steuern.
Die üblichen Schritte beim Erstellen eines Neuronalen Netzwerks (Modell erstellen, Modell trainieren, Modell validieren und verwenden) werden in
Keras mit Hilfe der Funktionen compile(), fit() und predict() durchgeführt.
2-3 Tensorflow
Tensorflow ist ein Framework für Machine Learning, das insbesondere für Anwendungen in der Bild- und Spracherkennung genutzt wird. Tensorflow bietet Programmierschnittstellen für verschiedene Programmiersprachen an, insbesondere Python, Java und C++, davon ist die meistgenutzte und stabilste Schnittstelle die Python API. Die Dokumentation der Tensorflow-API ist umfangreich und die zur Verfügung gestellten Beispiele können durch Ausführung der verlinkten Colab-Notebooks praktisch nachvollzogen werden.
Tensorflow wird zunächst für Aufgaben in der Bild- und Videobearbeitung eingesetzt, sowohl für Aufgaben der Bilderkennung (ist ein Objekt da?) als auch der Bild-Klassifikation (um welches Objekt handelt es sich?). Das Trainieren eines Modells in der Bildklassifikation ist sehr aufwendig - hier kann man mit Tensorflow auf vortrainierte Modelle zurückgreifen und einfach diese für die Klassifikation verwenden.
https://www.tensorflow.org/guide/tensorimport tensorflow as tfimport numpy as nprank_3_tensor = tf.constant([[[0, 1, 2, 3, 4],[5, 6, 7, 8, 9]],[[10, 11, 12, 13, 14],[15, 16, 17, 18, 19]],[[20, 21, 22, 23, 24],[25, 26, 27, 28, 29]],])print(rank_3_tensor)
2-4 Bilderkennung mit Keras und Tensorflow
Das folgende Beispiel zeigt, wie ein Künstliches Neuronales Netzwerk für die Ziffernerkennung mit Hilfe von Keras trainiert und für die Klassifikation verwendet wird. Das Ziel ist, ein Modell zu erstellen und zu trainieren, das handgeschriebene Ziffern (grau-weiß-Bilder im Format 28x28 Pixel, die die Ziffern 0,1,2,...,9 darstellen) korrekt klassifizieren kann.
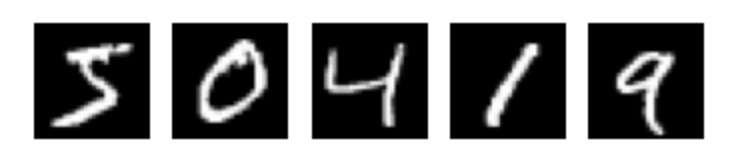
Unser Beispiel für Ziffernerkennung ist an das Simple MNIST convnet aus der Sammlung der Keras-Codebeispiele angelehnt. Der vollständige Quellcode mit zusätzlichen Erläuterungen ist als Google Colab Notebook online verfügbar.
Schritt 1: Daten einlesen und vorbereiten
Als Trainings- und Validierungsdatensatz werden 60.000 Ziffern-Bilder aus dem MNIST-Ziffern-Datensatz verwendet.
Der MNIST-Ziffern Datensatz kann direkt über Keras geladen werden.
Die Datenvorbereitung bedeutet, dass die
Bild-Daten in eine vorgegebene numerische Form umgewandelt, normalisiert und codiert werden müssen.
Verwendete Funktionen: load_data(), reshape(), to_categorical()
Ausgabeimport numpy as npimport matplotlib.pyplot as pltfrom keras.datasets import mnistfrom keras.utils import to_categorical, plot_modelfrom keras.models import Sequentialfrom keras.layers import Conv2D, MaxPooling2D, Dense, Flattenprint("1. Lade MNIST-Datensatz")(trainX, trainY), (testX, testY) = mnist.load_data()# Ausgabe der Dimensionen des Datensatzesprint('Train: X=%s, Y=%s' % (trainX.shape, trainY.shape))print('Test: X=%s, Y=%s' % (testX.shape, testY.shape))print("2. Datenvorbereitung")trainX = trainX.reshape((trainX.shape[0], 28, 28, 1))testX = testX.reshape((testX.shape[0], 28, 28, 1))# Daten werden in den Bereich [0, 1] normalisierttrainX = trainX.astype("float32") / 255.0testX = testX.astype("float32") / 255.0# Zielvariable wird numerisch codierttrainY = to_categorical(trainY)testY = to_categorical(testY)print('Train: X=%s, Y=%s' % (trainX.shape, trainY.shape))print('Test: X=%s, Y=%s' % (testX.shape, testY.shape))

Schritt 2: Modell definieren und trainieren
In diesem Schritt wird ein Deep Learning-Modell erstellt, für die Trainingsphase konfiguriert
und anschließend anhand der zuvor festgelegten Trainingsdaten trainiert.
Das Modell wird durch Hinzufügen passender Schichten erstellt. Für jede Schicht kann eine Aktivierungsfunktion angegeben werden.
Verwendete Klassen: Sequential, Conv2D, MaxPooling2D, Flatten, Dense
Verwendete Methoden: compile(), summary(), fit(), save()
Ausgabe# Definiere das Modellprint("3. Definiere das Modell")model = Sequential()model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))model.add(MaxPooling2D((2, 2)))model.add(Conv2D(64, (3, 3), activation='relu'))model.add(MaxPooling2D((2, 2)))model.add(Flatten())model.add(Dense(10, activation='softmax'))model.compile(loss='categorical_crossentropy', metrics=['accuracy'])model.summary()# Trainiere das Modellprint("4. Trainiere das Modell\n")model.fit(trainX, trainY, epochs=8, batch_size=64, verbose=2)# Speichere das Modellmodel.save('digits_model.keras')


Schritt 3: Modell evaluieren
In diesem Schritt wird die Güte des Modells bestimmt, dabei werden die Indikatoren loss und accuracy (Vertrauenswahrscheinlichkeit) verwendet.
Mit Hilfe des Parameters loss wurde bei Erstellung konfiguriert, welche Performance-Metrik während des Trainings minimiert werden soll.
Die Vertrauenswahrscheinlichkeit ist die Wahrscheinlichkeit, dass für eine Beobachtung eine richtige Vorhersage getroffen wird.
Verwendete Funktionen: evaluate()
score = model.evaluate(testX, testY, verbose=0)print("Test loss:", score[0]) # Ausgabe: Test loss: 0.03print("Test accuracy:", score[1]) # Ausgabe: Test accuracy: 0.99
Schritt 4: Modell für die Klassifikation neuer Bilder verwenden
In diesem Schritt wird das zuvor erstellte Modell verwendet, um neue Bilder korrekt zu klassifizieren.
4-1 Bild laden
Zunächst muss das zu klassifizierende Bild geladen und numerisch dargestellt werden.
Konkret wird hier ein Bild, das die Ziffer 5 darstellt, aus einer URL
geladen und in die von dem Modell benötigte numerische Darstellung umgewandelt.
Die selbstdefinierte Funktion prepare_image() hat die Aufgabe, ein als URL übergebenes
Bild zu laden und numerisch codiert als NumPy-Array darzustellen.
Verwendete Funktionen: load_img(), img_to_array()
from keras.preprocessing import imagefrom keras.utils import get_filedef prepare_image(img_url):'''Funktion lädt ein Bild aus einer URLund stellt es numerisch codiert als NumPy-Array dar'''img = Nonetry:file = get_file('fname',img_url) # Lade die Datei aus der URL in eine lokale Datei# Lade Bild im PIL-Format, 28x28 Pixelimg = image.load_img(file, color_mode = 'grayscale', target_size=(28, 28))# Wandle es in ein Array umimg = image.img_to_array(img)img = img.reshape(1, 28, 28, 1)img = img.astype('float32') / 255.0except Exception as error:print("Error: %s" % error)return img# Test-Bild laden und codieren: digit-5 kann ersetzt werden durch digit-7 etc.img_url = 'https://elab2go.de/demo-py1/images/digit-5.png'img = prepare_image(img_url)print(img) #
4-2 Modell laden und Vorhersage durchführen
Das Modell wird aus der zuvor gespeicherten *.keras Datei geladen.
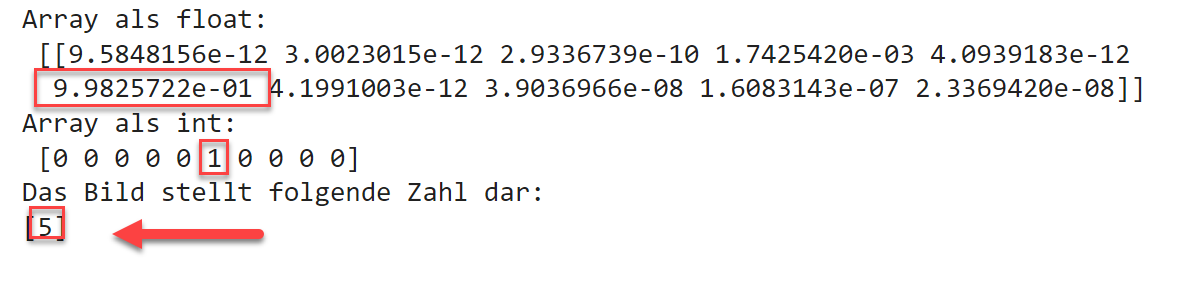
Die Klassifikation mittels der predict-Funktion liefert als Ergebnis ein NumPy-Array aus 9 Werten zurück,
wobei eine 1 an der i-Stelle i bedeutet, dass das Bild als Zahl i klassifiziert wurde.
Verwendete Funktionen: load_model(), predict()
Ausgabe für das Bild digit-5.pngfrom keras.models import load_model# Modell aus Datei ladenmodel = load_model('digits_model.keras')# Vorhersage / Klassifikation erstellenarr = model.predict(img)# Das Ergebnis ist ein Array z.B. [0,0,0,0,1,0,0,0,0]print("Array als float:\n", arr)# Konvertiere digit_arr in ein ganzzahliges Arrayarr = (np.rint(arr[0])).astype(int)print("Array als int:\n", arr)print("Das Bild stellt folgende Zahl dar:")print(np.where(arr == 1)[0])
Autoren, Tools und Quellen
Autor:
Prof. Dr. Eva Maria Kiss
Tools:
- Python: python.org/
- Anaconda: anaconda.com/
- Jupyter Notebook / JupyterLab: jupyter.org/
- Visual Studio Code (VSCode): code.visualstudio.com/
- Spyder: spyder-ide.org/
elab2go-Links
- [1] Datenverwaltung und -Visualisierung mit Pandas: elab2go.de/demo-py2/
- [2] Clusteranalyse mit scikit-learn: elab2go.de/demo-py3/
- [3] Predictive Maintenance mit scikit-learn: elab2go.de/demo-py4/
- [4] Machine Learning mit Keras und Tensorflow: elab2go.de/demo-py5/
Quellen und weiterführende Links
- [1] Offizielle Python Dokumentation bei python.org: docs.python.org/3/tutorial/
sehr umfangreich, Nachschlagewerk, hier findet man Dokumentationen für verschiedene Python-Versionen - [2] Python Tutorial: evamariakiss.de/tutorial/python/ – zum Nachschlagen der wichtigsten Python-Befehle, mit Selbsttest / Quiz
- [3] NumPy: numpy.org/ – Mehrdimensionale Arrays, Mathematische Funktionen, Zufallszahlen
- [4] Matplotlib: matplotlib.org/ – Datenvisualisierung, Plotten
- [5] Pandas: pandas.pydata.org/ – Datenverwaltung, Datenvorbereitung, DataFrames, Series
- [6] Scikit-Learn: scikit-learn.org – Algorithmen für Maschinelles Lernen
- [7] Keras: keras.io – Künstliche Neuronale Netzwerke, Deep Learning