Wie groß ist der Anteil erneuerbarer Energien an der Stromproduktion? – Eine grafische Analyse
Dieser Workshop beschreibt die Schritte zur Durchführung einer interaktiven Visualisierung der Stromerzeugung und des Stromverbrauchs in Deutschland mit Hilfe der Python-Bibliotheken für Datenanalyse NumPy, Matplotlib und Pandas. Die Fragestellung lautet: Wie ändert sich die Erzeugung von Strom insgesamt, Solar- und Windenergie über die Jahre? Reicht die Energiegewinnung über erneuerbare Energien aus, um den Verbrauch zu decken? Um diese Fragen zu beantworten, werden die Energie-Daten in ein Python-Notebook eingelesen und grafisch dargestellt.
Motivation
Im Rahmen der Energiewende wird europaweit angestrebt, fossile Energien nach und nach durch erneuerbare Energien wie Solar- und Windenergie zu ersetzen. Doch wie weit ist die Energiewende in Deutschland heute fortgeschritten?
Die großen Übertragungsnetzbetreiber (50Hertz, Amprion, TenneT und TransnetBW) stellen Rohdaten für Stromerzeugung und -Verbrauch zur Verfügung. Diese können an sich auch einfach mit Excel aufbereitet und grafisch dargestellt werden.
Eine flexiblere und interaktive Analyse kann dank der Python-Bibliotheken für Datenanalyse NumPy, Matplotlib und Pandas durchgeführt werden. Das vorliegende Tutorial soll auch Python-Einsteiger befähigen, interaktive Visualisierungen der Stromerzeugung und des Stromverbrauchs zu erstellen.
Übersicht
- 1 Vorbereitende Schritte
1-1 Entwicklungsumgebung
1-2 Python-Pakete installieren
1-3 Python-Pakete importieren - 2 Analyse der Stromerzeugung
2-1 Stromerzeugung-Daten einlesen
2-2 Farbschema festlegen
2-3 Stromerzeugungs-Daten als Tabelle
2-4 Stromerzeugungs-Daten als Diagramm
2-5 Konventionelle vs. Erneuerbare Energien
2-6 Interaktive Visualisierung - 3 Analyse des Stromverbrauchs
3-1 Stromverbrauchs-Daten einlesen
3-2 Stromverbrauchs-Entwicklung (aggregiert, monatlich)
3-3 Stromverbrauchs-Entwicklung (aggregiert, jährlich) - 4 Stromerzeugung vs. Stromverbrauch
Der Workshop ist als Google Colab Notebook online verfügbar:
1 Vorbereitung
1-1 Skript erstellen
Für die Programmierung der Datenanalyse wird eine Python-Entwicklungsumgebung benötigt. Häufig verwendete Python-Entwicklungsumgebungen sind Visual Studio Code, Spyder oder auch web-basierte Plattformen wie Jupyter Notebook oder Google Colab. Hier verwenden wir Google Colab, da so keine Installation erforderlich ist, lediglich Anmeldung mittels GMail.
Nachdem die Entwicklungsumgebung feststeht und geöffnet ist, erstellen wir in Google Colab ein neues Python-Notebook, in das dann die benötigten Python-Anweisungen eingefügt werden.
1-2 Python-Pakete installieren
Um Pakete verwenden zu können, müssen sie zuvor mit Hilfe des pip-Befehls installiert werden. Z.B.
pip install matplotlib pip install pandas
Pip ist das Standardpaketverwaltungssystem von Python. Die allgemeine Syntax eines Pip-Befehls lautet pip befehl paket optionen. Der Befehl ist einer von: list, show, install, uninstall. Die Optionen können auf zwei Arten angegeben werden: einerseits ausführlich, beispielsweise pip --help, oder in einer Kurzform, beispielsweise in pip -h.
Pakete mit pip verwalten
Dieses Beispiel zeigt, wie man pip verwendet, um Pakete aufzulisten,
Informationen für ein bestimmtes Paket anzuzeigen und ein Paket zu installieren / aktualisieren / deinstallieren.
pip --help pip list pip show numpy, pandas pip install pandas pip install numpy --update pip uninstall numpy
1-3 Python-Pakete importieren
Python-Bibliotheken und -Funktionen werden mit dem Befehl import importiert, gefolgt vom Namen der zu importierenden Bibliothek, zum Beispiel import numpy. Nach dem Import einer Bibliothek können alle ihre Klassen und Funktionen verwendet werden, indem der Name der Bibliothek dem Klassen- oder Funktionsnamen vorangestellt wird, wie in numpy.array oder numpy.linspace.
Python Paketmanagement
Beim Importieren von Paketen / Modulen / Klassen / Funktionen wird die Punkt-Notation verwendet, um die Zugehörigkeit zu kennzeichnen. z.B. paket.modul.klasse. Es können auch Alias-Namen für Pakete und Module vergeben werden, dies sind Kurznamen, die die Verwendung im Code vereinfachen.
import pandas as pd # Wird für Datenverwaltung und Datenbereinigung benötigtimport matplotlib.pyplot as plt # Wird für die Visualisierung benötigt
2 Analyse der Stromerzeugung
2-1 Daten zur Stromerzeugung einlesen
Die Daten zur Stromerzeugung sind zunächst in einer CSV-Datei hinterlegt,
die in der ersten Zeile die Jahre als Spaltenüberschriften enthält, und in den
Spalten die verschiedenen Energiearten.
Die CSV-Datei mit den Stromerzeugungs-Daten kann hier heruntergeladen werden:
stromerzeugung_de_2018-2023.csv
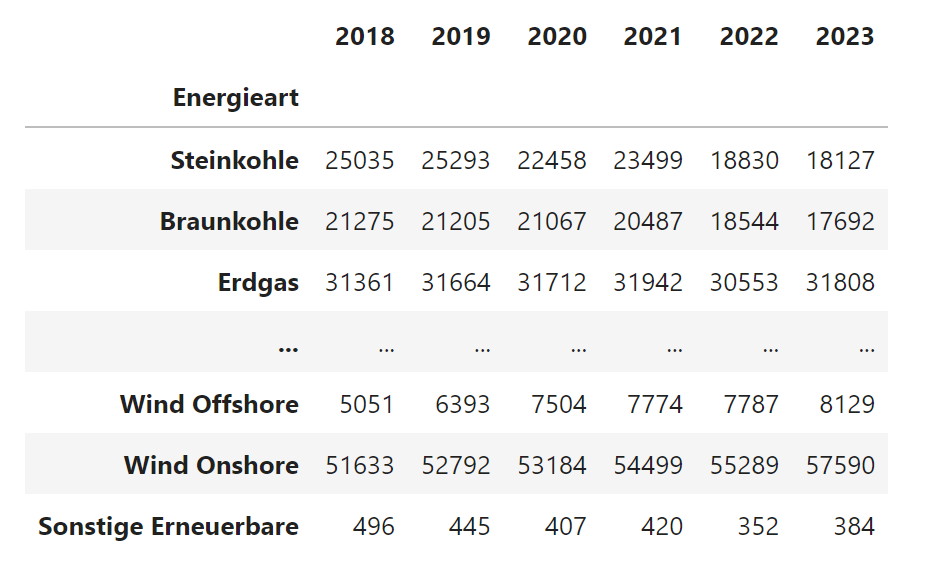
"Energieart","2018","2019","2020","2021","2022","2023" "Steinkohle","25035","25293","22458","23499","18830","18127" "Braunkohle","21275","21205","21067","20487","18544","17692" "Erdgas","31361","31664","31712","31942","30553","31808" "Erdöl","4271","4356","4373","4184","3966","4083" "Kernenergie","9516","9516","8114","8114","4056","4056" ... "Solar","42804","45299","48206","53302","57744","63066" "Wind Offshore","5051","6393","7504","7774","7787","8129" "Wind Onshore","51633","52792","53184","54499","55289","57590" "Sonstige Erneuerbare","496","445","407","420","352","384"
Mit Hilfe des Python-Pakets Pandas kann man tabellenartige Daten einlesen, bearbeiten und visualisieren. Dafür wird eine spezielle Datenstruktur "DataFrame" eingesetzt. Für das Einlesen der Daten aus der CSV-Datei wird hier die Pandas-Funktion read_csv verwendet. Der Funktion werden zwei Parameter übergeben: index_col=0 legt fest, dass die erste Spalte die sogenannte Index-Spalte ist und die Zeilenüberschriften enthält. sep="," legt fest, dass als Trennzeichen zwischen den Einträgen das Komma verwendet wird. Die Funktion liest die Daten aus der angegebenen Datei und speicher sie in einem DataFrame df_erz.
Python-Code
# Lese CSV-Datei mit Stromerzeugungsdaten ein# die erste Spalte enthält Zeilenüberschriftenfile = "https://www.elab2go.de/demo-py2/stromerzeugung_de_2018-2023.csv"df_erz = pd.read_csv(file, index_col=0, sep=",")# Ersetze fehlende Werte mit 0df_erz = df_erz.fillna(0)# Hilfs-Funktion zur formatierten Ausgabedef display_dataframe( df, rows=6, cols=None):with pd.option_context('display.max_rows', rows,'display.max_columns', cols):display(df);display_dataframe(df_erz)
Ausgabe
Python Bibliotheken
2-2 Farbschema festlegen
Damit unsere tabellarische und grafische Visualisierung leicht lesbar ist, wird für jede Energieart eine aussagekräftige Farbe festgelegt. Dafür werden zwei Datenstrukturen angelegt: ein Dictionary dirct_colormap, das für jede Energie-Art die passende Farbe angibt, und eine Liste, die lediglich die Namen der verwendeten Farben enthält.
Python-Code
# Farbschema als Dictionarydict_konv = {'Steinkohle': '#6c757d', 'Braunkohle':'peru','Erdgas': 'peachpuff','Erdöl': 'slateblue','Kernenergie': '#dc3545', 'Ersatzbrennstoff': 'gray','Sonstige Konventionelle': 'lightgray'}dict_ern = {'Geothermal': 'coral', 'Pumpspeicher': 'deepskyblue','Wasserkraft': 'lightskyblue', 'Wasser Reservoir': 'dodgerblue','Biomasse': 'olive','Solar': '#ffc107', 'Wind Offshore': 'lightblue','Wind Onshore': 'lightcyan','Sonstige Erneuerbare': 'lightgray'}dict_colormap = dict_konv | dict_ern # Komplettes Farbschema# Farbschema als Listecolormap_konv = list(dict_konv.values());colormap_ern = list(dict_ern.values());colormap = colormap_konv + colormap_ern;print("Farbschema als Schlüssel-Wert_Paare");print(dict_colormap);
Ausgabe

Ändere das Farbschema ab, so dass erneuerbare Energien in Grün-Schattierungen angezeigt werden.
2-3 Stromerzeugung-Daten als Tabelle
In diesem Schritt werden die als DataFrame df_erz gespeicherten Stromerzeugungs-Daten eingefärbt. Eine Besonderheit von Pandas DataFrames ist, dass man für eine verbesserte visuelle Darstellung jedem Eintrag ein Stil-Element zuordnen kann. Hier wird dafür die Funktion apply_color() eingesetzt, die jeder Zeile / Energie-Art ihre eigene Hintergrundfarbe zuordnet.
Python-Code
def apply_color(df):list1 = ['background-color:']*len(df.index) # 16x 'background-color'list2 = colormap # 16 Farben# Elementweise Verknüpfung der beiden Listenstyle_list = [s1+s2 for s1,s2 in zip(list1,list2)]return style_listdf_erz.style.apply(apply_color)
Ausgabe
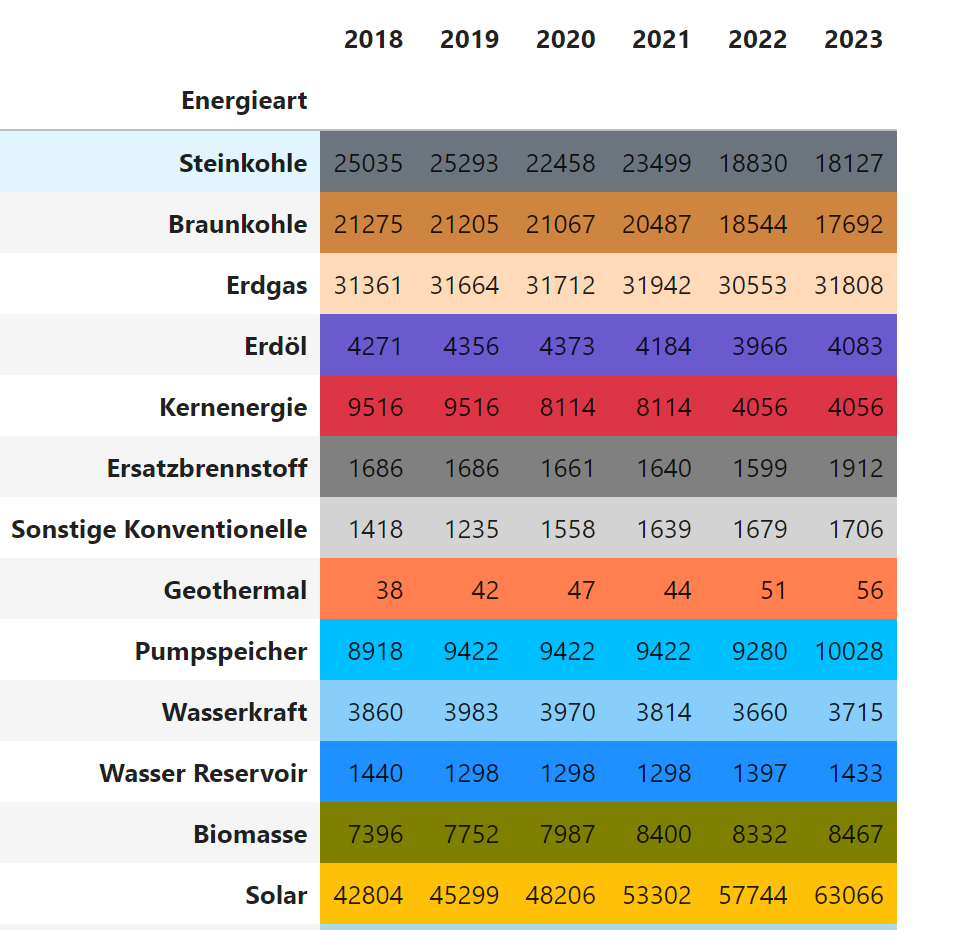
Ändere die Funktion apply-color so ab, dass anstelle der Hintergrundfarbe die Textfarbe geändert wird.
2-4 Stromerzeugungs-Daten als Diagramm
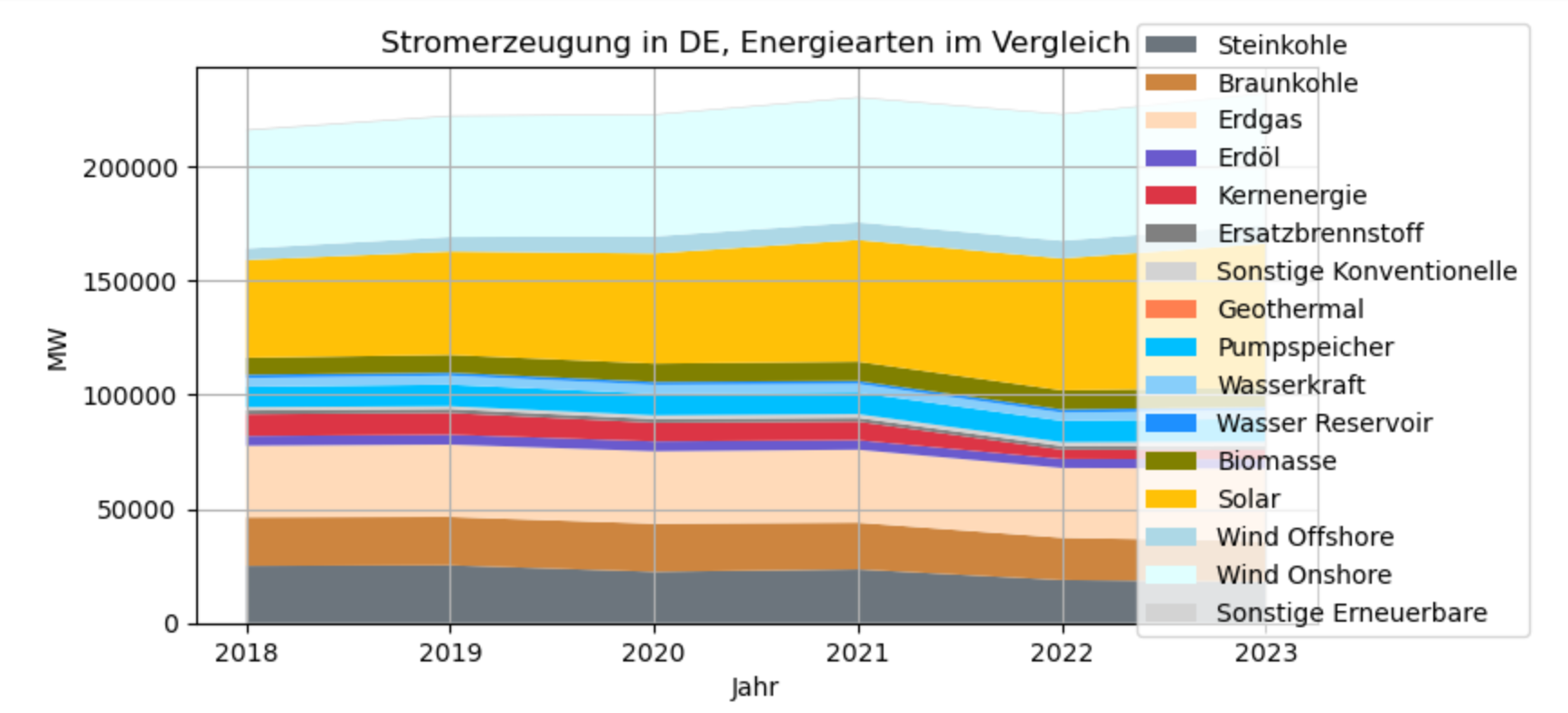
Als Nächstes erfolgt die grafische Darstellung der Stromerzeugungsdaten in einen Stapeldiagramm. Die Funktion stackplot der Python-Bibliothek Matplotlib erhält als Parameter die Spalten des DataFrames df_erz und die zuvor erstellte colormap als farbliche Codierung. Aus dem Diagramm ist nun klar ablesbar, dass der Anteil an erneuerbaren Energien steigt, insbesondere Wind Onshore und Solar / Photovoltaik.
Python-Code
fig = plt.figure(figsize=[8, 4])plt.stackplot(df_erz.columns, df_erz,colors=colormap, labels=df_erz.transpose().columns);plt.title('Stromerzeugung in DE, Energiearten im Vergleich')plt.grid(True)plt.xlabel('Jahr');plt.ylabel('MW');plt.legend(bbox_to_anchor=(1.2, 1.1));
Ausgabe
2-5 Konventionelle vs. erneuerbare Energien
Wie ist die Entwicklung bei der Erzeugung eneuerbarer Energien vs. konventioneller Energien? Wir erstellen zwei separate Diagramme für konventionelle und erneuerbare Energien, und zeigen sie nebeneinander an.
Python-Code
df_konv = df_erz.iloc[0:7, :] # Konventionell= Spalten 0 bis 7df_ern = df_erz.iloc[8:16, :] # Erneuerbar = Spalten 8 is 16# Erstelle ein Diagramm mit zwei Subplots nebeneinanderfig, axs = plt.subplots(1, 2, figsize=(14, 5), sharey=False)plt.subplot(1,2,1)axs[0].stackplot(df_konv.columns, df_konv.iloc[1:8],colors=colormap_konv, labels=df_konv.transpose().columns);axs[0].set_title('Konventionell')axs[0].set_xlabel('Jahr'); axs[0].set_ylabel('MW'); axs[0].legend(loc='upper left');plt.subplot(1,2,2)axs[1].stackplot(df_ern.columns, df_ern.iloc[1:8],colors=colormap_ern, labels=df_ern.transpose().columns);axs[1].set_title('Erneuerbar')axs[1].set_xlabel('Jahr'); axs[1].set_ylabel('MW'); axs[1].legend(loc='upper left');fig.suptitle('Stromerzeugung in Deutschland 2018 bis 2023');
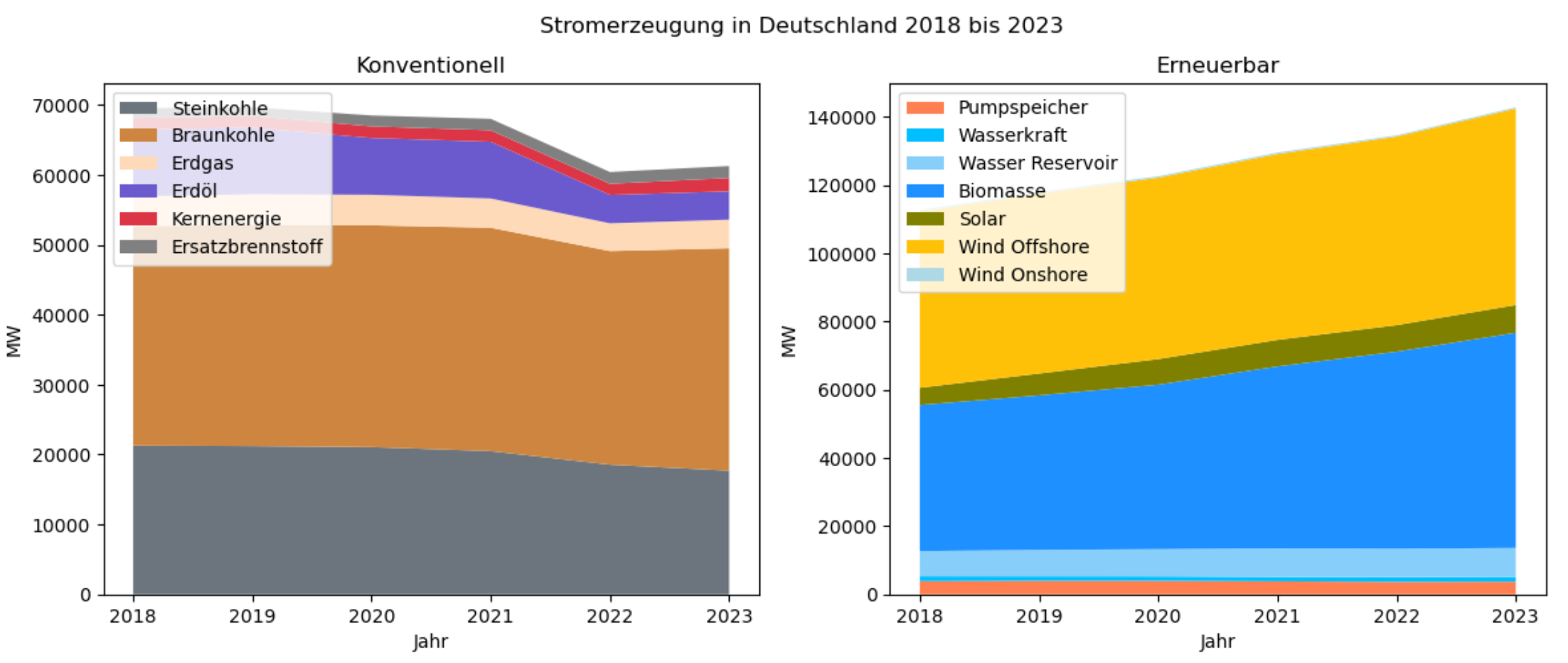
- Ändere die Anordnung der Bilder, so dass sie untereinander erscheinen.
- Ändere die Größe der Bilder.
- Erstelle ein neues Diagramm, in dem links nur Erdöl und Erdgas und rechts nur Wind und Solar angezeigt werden.
2-6: Interaktive Visualisierung
Die bisherigen Visualisierungen sind noch unübersichtlich, es werden zu viele Daten auf einem Diagramm dargestellt. Uns interessieren z.B. speziell die Energie-Arten Wind und Solar. Hier soll die Auswahl bestimmter Energie-Arten und Jahre mit Hilfe einer interaktiven Visualisierung ermöglicht werden.
Schritt 1: Hilfsfunktion select_data()
In Schritt 1 wird eine Funktion select_data() programmiert,
die die Auswahl eines Datums-Bereichs und bestimmter Energie-Arten / Zeilen ermöglicht und für
die ausgewählten Daten ein Stapeldiagramm erstellt.
Diese Funktion wird in einem zweiten Schritt mit den Ein- und Ausgabefeldern der
grafischen Benutzeroberfläche verknüpft.
Python-Code
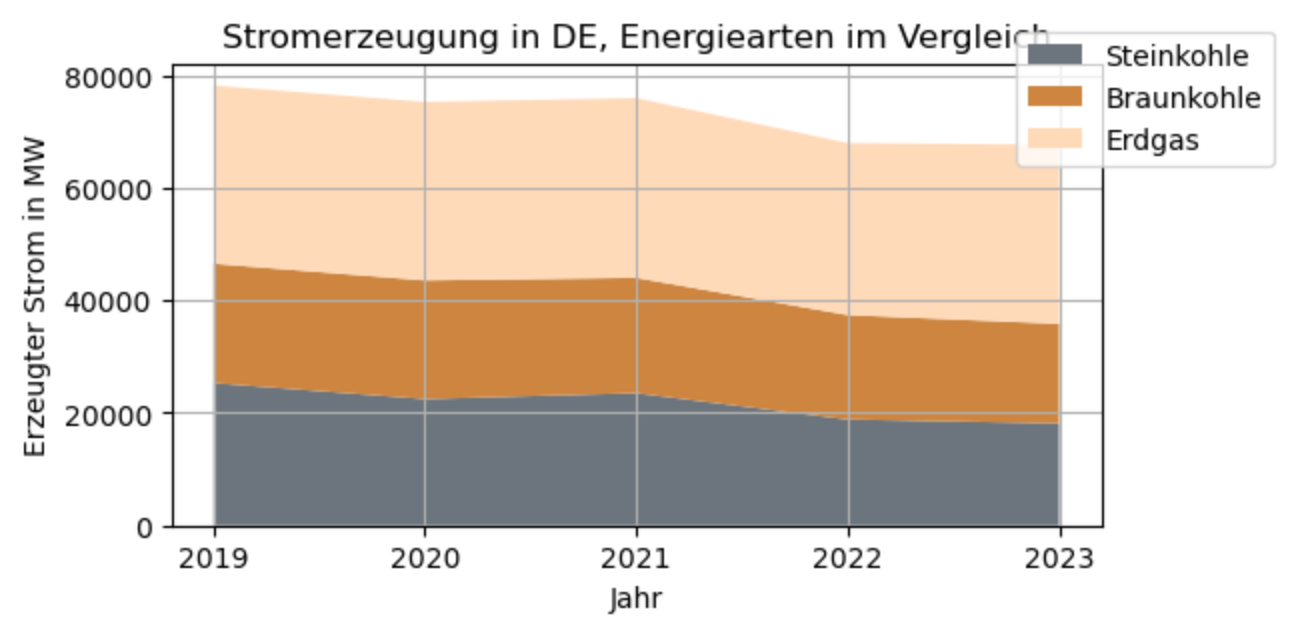
# (1) Definiere Funktion select_data() für die Auswahl von Datum + Zeilendef select_data(datumVon, datumBis, zeilen):df = df_erz.loc[zeilen, datumVon:datumBis];fig = plt.figure(figsize=[6, 3])cmap = list(dict_colormap[k] for k in df.index)plt.stackplot(df.columns, df, colors=cmap, labels=df.transpose().columns);plt.title('Stromerzeugung in DE, Energiearten im Vergleich')plt.grid(True);plt.xlabel('Jahr');plt.ylabel('Erzeugter Strom in MW');plt.legend(bbox_to_anchor=(1.2, 1.1));plt.show();# (2) Funktion testenselect_data('2019', '2023', ['Steinkohle', 'Braunkohle', 'Erdgas'])
Jupyter Widgets verwenden: elab2go.de/demo-py1/jupyter-widgets.php
Die Funktion select_data() soll mit unterschiedlichen Parametern aufgerufen werden, z.B. sollen die Energiearten Solar, Wind Onshore und Wind Offshore gegenübergestellt werden.
Ausgabe
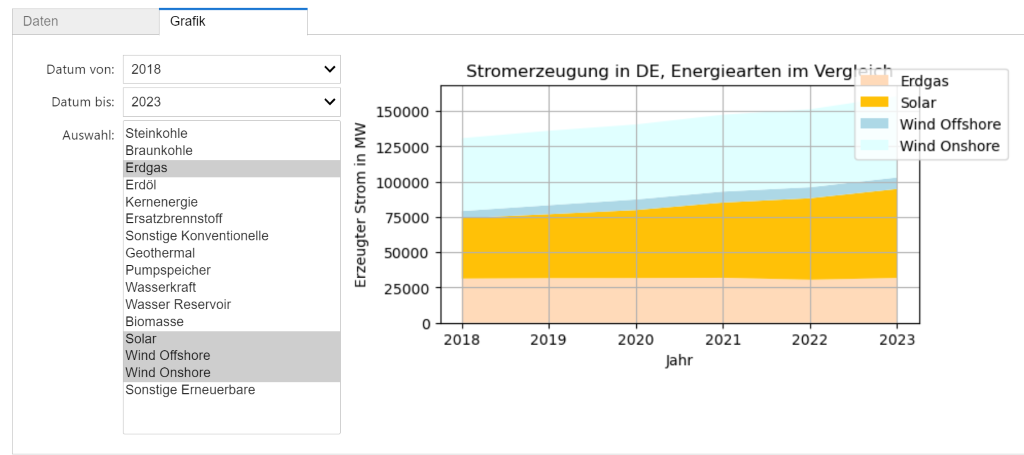
Schritt 2: Funktion select_data mit Eingabefeldern verknüpfen
Jupyter Widgets sind Steuerelemente, die über die Python-Bibliothek ipywidgets zur Verfügung gestellt werden,
und mit deren Hilfe man ein Python Notebook um grafische Benutzeroberflächen erweitern kann.
Die Bibliothek ipywidgets verfügt insbesondere über eine Funktion interactive_output,
die die Erstellung einer interaktiven Visualisierung über eine Hilfsfunktion (hier: select_data)
ermöglicht.
Python-Code
from ipywidgets import Output, Dropdown, SelectMultiple, Tab, VBox, HBox, Layoutfrom ipywidgets import interactive_outputout1, out2 = Output(), Output()with out1: # Ausgabe für das erste Tab: Die Daten-Tabellefile = "https://www.elab2go.de/demo-py2/stromerzeugung_de_2018-2023.csv"df_erz = pd.read_csv(file, index_col=0)df_erz = df_erz.fillna(0)display_dataframe(df_erz)with out2: # Ausgabe für das zweite Tab: Das Diagramm# Widgets für die Auswahl des Datums und der Zeilendatum_von = Dropdown(description='Datum von: ', options=df_erz.columns, value='2018')datum_bis = Dropdown(description='Datum bis: ', options=df_erz.columns, value='2023')ui_zeilen = SelectMultiple(description='Auswahl:', options=df_erz.index,value=['Erdgas', 'Solar', 'Wind Offshore', 'Wind Onshore'],rows=18)out = interactive_output(select_data,{'datumVon': datum_von, 'datumBis': datum_bis,'zeilen': ui_zeilen});display(HBox([VBox([datum_von, datum_bis, ui_zeilen]), out]))tab = Tab(children = [out1, out2], layout=Layout(width='100%'))tab.set_title(0, 'Daten')tab.set_title(1, 'Grafik')display(tab)
Interaktive Visualisierung
3 Analyse des Stromverbrauchs
In diesem Abschnitt werden nun Stromverbrauchs-Daten analysiert, mit denselben Pandas-Datenstrukturen und Funktionen, die auch in den vorigen Abschnitten eingesetzt wurden. Da die Daten hier in stündlicher Auflösung vorliegen, müssen neue Funktionen eingesetzt werden, um die Daten auf Monats- und Jahres-Ebene zu aggregieren.
3-1 Daten zum Stromverbrauch einlesen
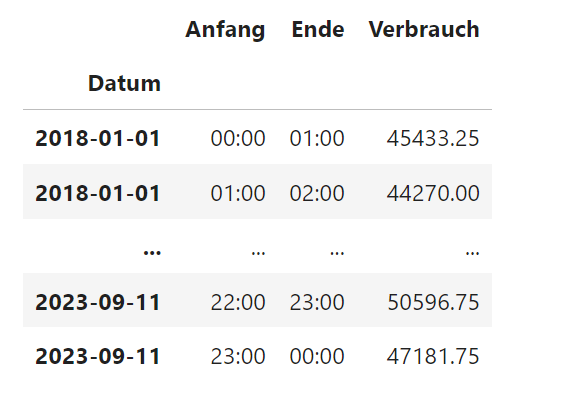
Die Daten zum Stromverbrauch sind ebenfalls in einer CSV-Datei hinterlegt, deren erste Zeile die Spaltenüberschriften enthält.
Datum;Anfang;Ende;Verbrauch;Residuallast;Pumpspeicher 01.01.2018;00:00;01:00;45.433,25;14.015,5;1.393,75 01.01.2018;01:00;02:00;44.270;11.634,25;1.793,75 ... 11.09.2023;22:00;23:00;50.596,75;48.413;37,5 11.09.2023;23:00;00:00;47.181,75;45.421,5;193
Die CSV-Datei mit den Stromerzeugungs-Daten kann hier heruntergeladen werden:
stromverbrauch_de_2018-2023_stunde.csv
Wie zuvor die Stromerzeugungsdaten werden auch die Stromverbrauchsdaten mittels der Pandas-Funktion read_csv in ein DataFrame eingelesen, diesmal nennen wir es einfach df.
Python-Code
# Lese CSV-Datei mit Stromverbrauchsdaten ein,# die 0-te Spalte enthält den Tag als Zeilenüberschriftenfile = 'https://www.elab2go.de/demo-py2/stromverbrauch_de_2018-2023_stunde.csv'df = pd.read_csv(file, parse_dates=True, dayfirst=True,index_col=0, thousands=r'.', decimal=r',', sep=';')df = df.fillna(0) # Ersetze fehlende Werte mit 0display_dataframe(df, 4) # Zeige erste und letzte zwei Zeilen zur Kontrolle an
3-2 Stromverbrauch (stündlich und monatlich)
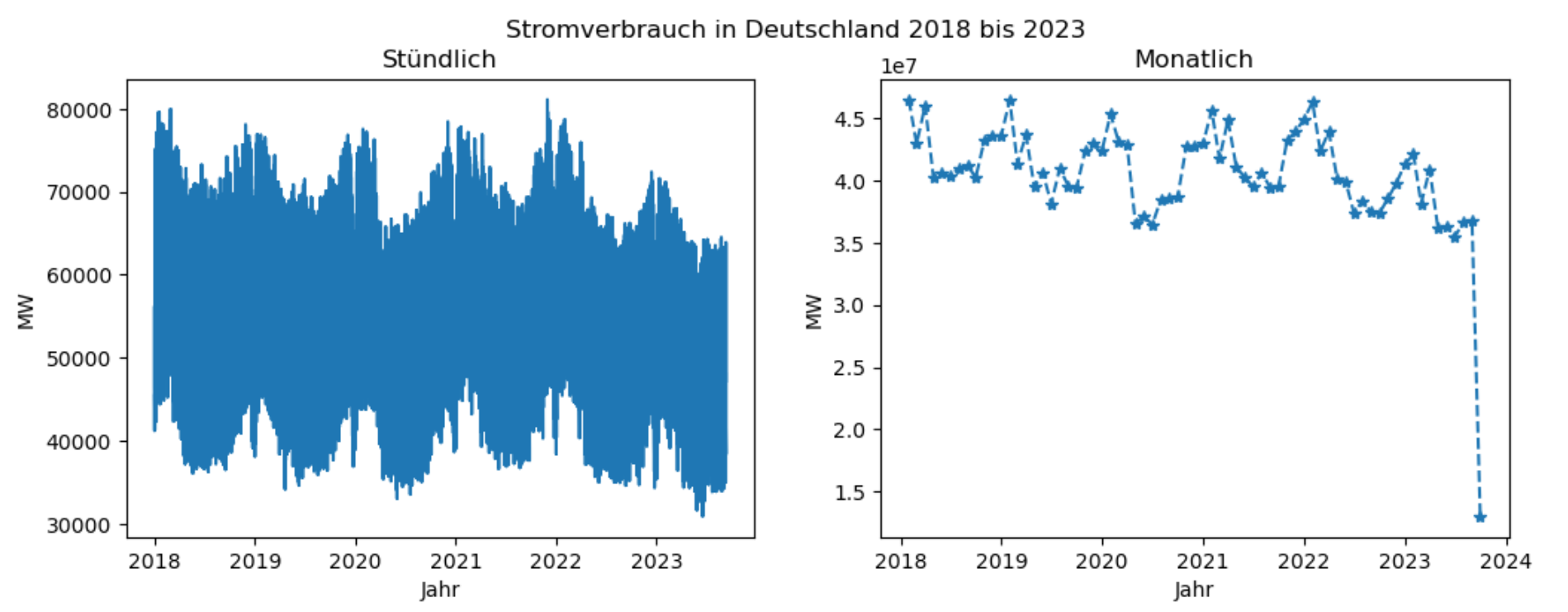
Wie hat sich der Stromverbrauch in den Jahren 2018 bis 2023 entwickelt? Dafür visualisieren wird die Daten aus der Spalte "Verbrauch", zunächst in der ursprünglichen Auflösung, dann in einer aggregierten monatlichen Auflösung. Die Aggregation wird in Python mit Hilfe der Pandas-Methode resample() umgesetzt.
Python-Code: Stündlicher und monatlicher Stromverbrauch
# Behalte aus dem Datensatz nur die angegebenen Spaltendf_verbrauch = df.copy().iloc[:,[0,1,2]];# Zeige erste und letzte zwei Zeilen zur Kontrolle andisplay_dataframe(df_verbrauch,4)# Monatsweise Aggregation der Spalte Verbrauchspalten = ['Verbrauch']# Gruppiere Spalte Verbrauch monatsweisedf_monat = df_verbrauch[['Verbrauch']].resample('M').sum()# Spalte Monat einfügendf_monat.insert(0, 'Monat', df_monat.index.month)
Ausgabe
Python-Code: Visualisierung des Stromverbrauchs
# Visualisierung der Datenfig, axs = plt.subplots(1, 2, figsize=(12, 4), sharey=False)plt.subplot(1,2,1)axs[0].plot(df_verbrauch['Verbrauch']);axs[0].set_title('Stündlich')axs[0].set_xlabel('Jahr');axs[0].set_ylabel('MW');plt.subplot(1,2,2)axs[1].plot(df_monat['Verbrauch'], '*--');axs[1].set_title('Monatlich')axs[1].set_xlabel('Jahr');axs[1].set_ylabel('MW');fig.suptitle('Stromverbrauch in Deutschland 2018 bis 2023');
Ausgabe
3-3 Stromverbrauchs-Entwicklung (jährlich)
Wir haben bisher die stündlichen Verbrauchswerte betrachtet. Für die Betrachtung des Stromverbrauchs pro Jahr aggregieren wir die stündlichen Werte.
Python-Code: Jährlicher Stromverbrauch
pd.set_option('display.float_format', '{:.2E}'.format)# Wähle Spalte Verbrauch ausspalten = ['Verbrauch']# Gruppiere jede der Spalten nach Jahrdf_jahr = df_verbrauch[spalten].resample('Y').sum()# Spalte Jahr einfügendf_jahr.insert(0, 'Jahr', df_jahr.index.year)df_jahr = df_jahr.rename(columns={"Verbrauch": "Verbrauch (MWh)"})# Zeige df_jahr Kontrolle andisplay_dataframe(df_jahr)
Ausgabe
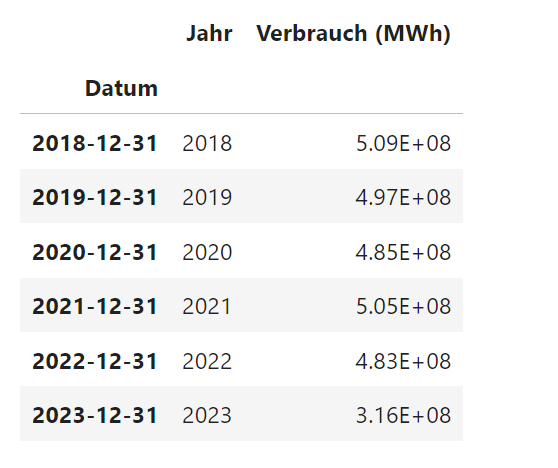
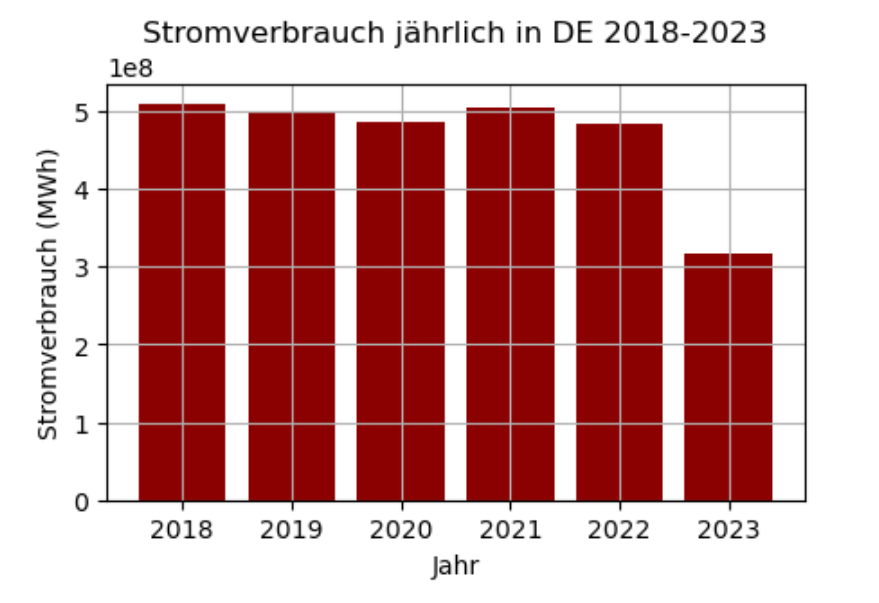
Der Abfall des Stromverbrauchs im Jahr 2023 liegt daran, dass für dies Jahr nicht die kompletten Daten vorliegen, sondern lediglich der Zeitraum 01.01.2023 bis 11.09.2023 erfasst wurde.
4 Vergleich: Stromerzeugung vs Stromverbrauch
Abschließend wird noch ein neues DataFrame df_vergleich angelegt, das Stromerzeugung und Stromverbrauch gegenüberstellt.Dem zunächst leeren DataFrame df_vergleich werden die Spalten 'Stromerzeugung' und 'Stromverbrauch' hinzugefügt, die aus den zuvor erstellten DataFrames df_erz und df_jahr ermittelt werden.
Die Spalte 'Stromerzeugung' enthält für jedes Jahr die gesamte Energieerzeugung und wird durch die Aggregation df_vergleich['Stromerzeugung'] = df_erzt[df_erzt.columns].sum(axis=1) in Zeile 3 ermittelt. Dafür wird das DataFrame für Stromerzeugung df_erz transponiert, so dass die Energie-Arten nun die Spaltenüberschriften sind und die Jahre die Zeilenüberschriften.
Die Spalte 'Stromverbrauch' enthält den Stromverbrauch des jeweiligen Jahres und wird der Spalte
'Verbrauch (MWh)' des zuvor berechneten DataFrames df_jahr entnommen:
df_vergleich['Stromverbrauch'] = list(df_jahr['Verbrauch (MWh)'])
Das neue DataFrame df_vergleich erhält als Index-Spalte (d.h. Zeilenüberschriften) den Index des DataFrames df_erzt, also die Jahre, und kann mit einem Linien- oder Balkendiagramm visualisiert werden.
Python-Code: Gegenüberstellung Stromerzeugung vs. Stromverbrauch
df_vergleich = pd.DataFrame()df_erzt = df_erz.transpose()df_vergleich['Stromerzeugung'] = df_erzt[df_erzt.columns].sum(axis=1)df_vergleich['Stromverbrauch'] = list(df_jahr['Verbrauch (MWh)'])df_vergleich.index = df_erzt.indexdisplay_dataframe(df_vergleich)fig = plt.figure(figsize=[5, 3])plt.plot(df_vergleich, '*--', label=df_vergleich.columns);plt.title('Stromerzeugung vs. Stromverbrauch ')plt.xlabel('Jahr');plt.ylabel('MW');plt.legend();
Ausgabe
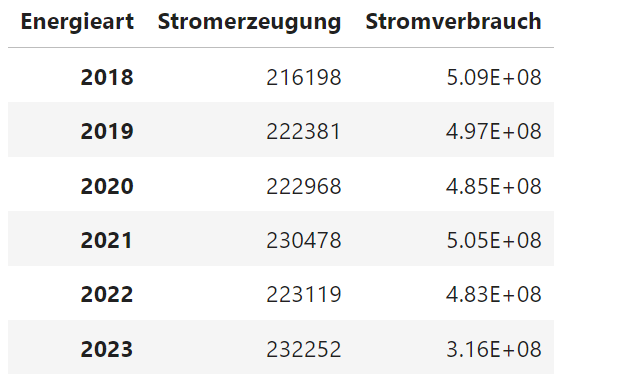
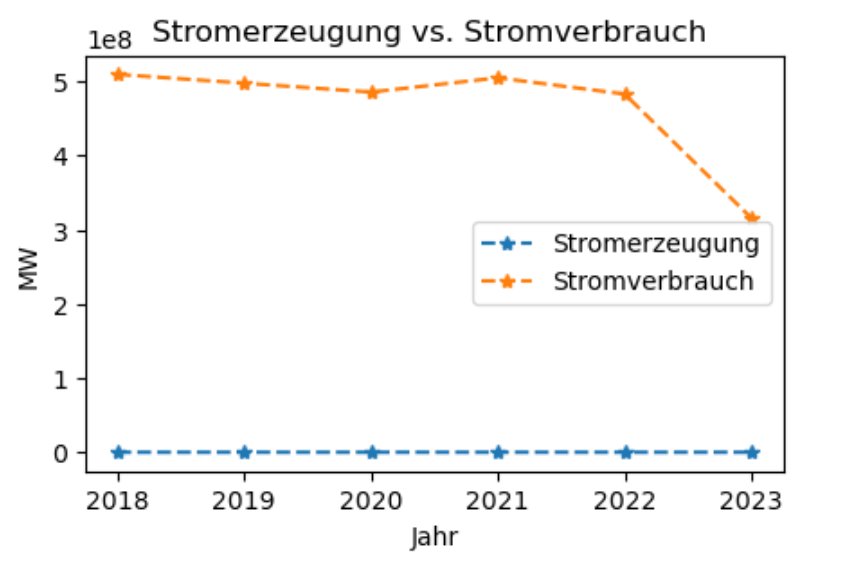
Der Abfall des Stromverbrauchs im Jahr 2023 liegt daran, dass für dies Jahr nicht die kompletten Daten vorliegen, sondern lediglich der Zeitraum 01.01.2023 bis 11.09.2023 erfasst wurde.
- Verwenden Sie anstelle des Linien-Diagramms einen anderen passenden Diagrammtyp, z.B. ein Balkendiagramm (gruppiert oder gestapelt). Beispiele zur Erstellung von Balkendiagrammen finden Sie in der Dokumentation des Pandas bar-plots.
- Wie würden Sie die Tabelle und grafische Darstellung interpretieren?
Autoren, Tools und Quellen
Autor:
Prof. Dr. Eva Maria Kiss
Tools:
- Python: python.org/
- Jupyter Notebook / JupyterLab: jupyter.org/
- Visual Studio Code (VSCode): code.visualstudio.com/
elab2go-Links
- [1] Datenverwaltung und -Visualisierung mit Pandas: elab2go.de/demo-py2/
- [2] Clusteranalyse mit scikit-learn: elab2go.de/demo-py3/
- [3] Predictive Maintenance mit scikit-learn: elab2go.de/demo-py4/
- [4] Machine Learning mit Keras und Tensorflow: elab2go.de/demo-py5/
Quellen und weiterführende Links
- [1] Python Dokumentation bei python.org: docs.python.org/3/tutorial/
- [2] Pandas: pandas.pydata.org/
- [3] PIP Packet Manager: pypi.org/project/pip/
- [4] Visual Studio Code: code.visualstudio.com/