Predictive Maintenance: Die Datenanalyse
Nachdem in Schritt 2: Datenerhebung des Predictive Maintenance-Prozesses die
Daten erhoben und in Schritt 3 die Daten bereinigt wurden,
wird nun im vierten Schritt die Datenanalyse durchgeführt.
Das Ziel der Datenanalyse ist die Ausarbeitung eines guten Vorhersagemodells für
die vorhandenen Datensätze. Falls für die Vergangenheitsdaten der Zustand (Ausfall ja / nein) mit erfasst wurde,
verwendet man Algorithmen des überwachten Lernens, z.B. Entscheidungsbäume oder Random Forests.
Falls für die Vergangenheitsdaten der Zustand nicht mit erfasst wurde, verwendet man Algorithmen des unüberwachten Lernens,
z.B. Clusteranalysen oder Isolation Forests.
Im Falle des Automotivedatensatzes, bei dem Sensorwerte von Motoren und deren Zustand (Ausfall JA/NEIN) erfasst wurden,
soll ein Entscheidungsbaum-Modell vorhersagen, bei welcher Kombination von Sensorwerten ein Ausfall eines Motors zu erwarten ist.
Das Modell
Ein Vorhersagemodell oder kurz Modell ist eine Funktion / Zuordnung, die die Merkmale einer Beobachtung auf die korrekten Zustände ("In Ordnung" oder "Ausfall") abbildet. In der praktischen Datenanalyse entsteht ein Modell, indem der Datensatz bzw. die Datentabelle, die bei der Datenerhebung gespeichert wurde, um eine Spalte y ergänzt wird, die den Zustand enthalten wird. Die Spalte y wird auch Zielvariable oder Vorhersagevariable genannt. In unserem Beispiel wird die Zielvariable konkret mit Ausfall bezeichnet und sie kann nur zwei Werte annehmen "ja" (d.h. Ausfall) und "nein" (d.h. in Ordnung).
| id | x1 | x2 | y |
|---|---|---|---|
| 1 | x_11 | x_12 | nein |
| 2 | x_21 | x_22 | nein |
| 3 | x_31 | x_32 | ja |
| 4 | x_41 | x_42 | ja |
Informell kann ein Modell als eine Zuordnungstabelle gesehen werden. Jede Zeile stellt eine Beobachtung dar, die n Merkmale x1, x2, ... xn hat. Die Vorhersage besteht darin, dass man für jede Zeile in die Spalte y, die der Zielvariablen bzw. dem Zustand entspricht, den korrekten Wert einträgt.
| id | temp | druck | ausfall |
|---|---|---|---|
| 1 | normal | hoch | nein |
| 2 | hoch | normal | nein |
| 3 | hoch | hoch | ja |
| 4 | hoch | normal | ja |
In diesem Beispiel entsprechen die Merkmale temp und druck den Spalten x1, x2 und die Spalte y = ausfall ist die Zielvariable.
Zuordnung 1: Wenn die Temperatur normal und der Druck hoch ist, wird kein Ausfall vorhergesagt.
Zuordnung 3: Wenn Temperatur und Druck beide hoch sind, wird ein Ausfall vorhergesagt.
Ein gutes Vorhersagemodell sollte nicht nur fehlerhafte Zuordnungen in schon bekannten Beobachtungen vermeiden, sondern auch aus den bekannten historischen Beobachtungen Vorhersagen für zukünftige Datensätze treffen können.
In der Datenanalyse unterscheidet man zwischen Klassifikations- und Regressionsmodellen und muss wissen, für welchen Anwendungsfall welches Modell angewendet werden kann. Wir benötigen hier ein Klassifikationsmodell, das Gruppenzugehörigkeiten vorhersagt, also ob eine Beobachtung in der Gruppe "In Ordnung" oder in der Gruppe "Ausfall" liegt.
Der Entscheidungbaum
Ein einfaches und intuitiv nutzbares Klassifikationsmodell ist der Entscheidungsbaum, der hierarchisch aufeinanderfolgende Entscheidungen veranschaulicht. Ein Entscheidungsbaum besteht aus einer Wurzel, Kindknoten und Blättern, wobei jeder Knoten eine Entscheidungsregel und jedes Blatt eine Antwort auf die Fragestellung darstellt. Um eine Klassifikation eines einzelnen Datenobjektes abzulesen, geht man vom Wurzelknoten entlang des Baumes abwärts. Bei jedem Knoten wird ein Merkmal abgefragt und eine Entscheidung über die Auswahl des folgenden Knoten getroffen. Dies wird so lange fortgesetzt, bis man ein Blatt erreicht. Das Blatt entspricht der Klassifikation.
Ein Entscheidungsbaum enthält grundsätzlich Regeln zur Beantwortung von nur genau einer Fragestellung.
Mini-Beispiel (fortgesetzt)
Der Entscheidungsbaum für unser Mini-Beispiel gibt z.B. eine Antwort auf die Frage, bei welcher Kombination von Werten für die Merkmale temp und druck das das Gerät ausfallen wird. Als Eingabe benötigt der Baum eine Beobachtung, d.h. eine Kombination von Merkmalen, z.B. {temp=hoch, druck= normal}.
Entscheidungsbaum
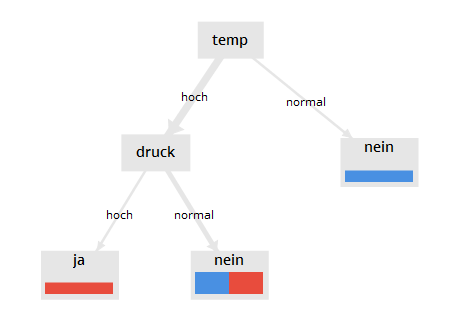
Der Entscheidungsbaum für unser Mini-Beispiel wurde aus RapidMiner heraus erzeugt.
Entscheidungsregeln
Der Entscheidungsbaum kann alternativ in Textform, als formatierte Auflistung der Entscheidungsregeln dargestellt werden. Die Entscheidung an der Wurzel ist linksbündig dargestellt. Die Kindknoten jeder weiteren Ebene werden durch Einrückung hervorgehoben.
temp = hoch
| druck = hoch: ja {nein=0, ja=1}
| druck = normal: nein {nein=1, ja=1}
temp = normal: nein {nein=1, ja=0}
Wir fangen bei der Wurzel an und wenden die Regeln des Baumes an, wobei an jedem Knoten
ein Attribut des Baumes abgefragt wird.
Erste Frage: ist temp hoch oder normal? temp ist hoch, also gehen wir nach links.
Zweite Frage: Ist druck hoch oder normal? druck ist hoch also gehen wir nach links.
Hier haben wir die Eingabe abgearbeitet und sind an einem Blatt angekommen.
Die Antwort lautet: ja, d.h. bei dieser Eingabe tritt ein Ausfall ein.
Wie entsteht ein gutes Vorhersagemodell?
Die in Schritt 2 erhobenen Daten werden zunächst in einen Trainings- und einen Testdatensatz aufgeteilt. Der Trainingsdatensatz (üblicherweise ca. 80% der Daten) wird zur Bestimmung des Modells herangezogen und der restliche Anteil der Daten (ca. 20%) wird als Testdatensatz zur Bewertung des Modells genutzt.

Ein gutes Vorhersagemodell entsteht, indem zunächst eine Modellfunktion mit Hilfe des Trainingsdatensatzes bestimmt wird. Mit Hilfe dieser Modellfunktion wird der Trainingsfehler als Differenz zwischen den errechneten und tatsächlichen Zuständen berechnet.
Anschließend wird das Modell mit Hilfe des Testdatensatzes bewertet. Mit Hilfe der zuvor bestimmten Modellfunktion werden die Zustände für den Testdatensatz berechnet und mit den tatsächlichen Zuständen verglichen, dies ergibt den Testfehler.
Ein gutes Vorhersagemodell hat zum Ziel, den Testfehler möglichst klein zu halten, z.B. unterhalb von 10%.
Klassifikation einer Beobachtung
Der Klassifikator ist das Resultat der Bestimmung des Modells anhand von den Trainingsdaten. Jede Kombination aus Merkmalen (Sensorwerte zu Temperatur, Laufbewegung, Druck, usw.) erhält eine eindeutige Zurordnung zu einem der Zustände "Ausfall" oder "In Ordnung".
Für neue aktuell erhobene Merkmalskombinationen kann eine Vorhersage über "Ausfall" oder "In Ordnung" anhand des Klassifikators erfolgen. Dies beantwortet dann die Frage: Fällt ein Bauteil mit diesen Werten zu Temperatur, Laufbewegung, Druck, usw. aus oder nicht? Und stellt damit die Basis für Schritt 5: Die Antwort/Lösung dar.
Vorhersage eines Ausfalls
Der mittels des Trainingsdatensatzes bestimmte und mittels des Validierungsdatensatzes bewertete Klassifikator wird nun genutzt um für ein zu überwachendes Bauteil oder einer Maschine, hier: einen Motor, eine Vorhersage zu treffen. Es werden die Sensordaten (hier: Druck und Temperatur) des Motors ermittelt und an eine Station übermittelt. Dort werden die Werte in den Klassifikator eingegeben und es erfolgt eine Klassifikation (Zuordung) des Bauteils in die Klasse "In Ordnung/OK" oder "Ausfall". Wenn eine Zuordnung zur Klasse "Ausfall" erfolgt, dann sprechen aufgrund des Modells die Sensorwerte des Motors für einen Ausfall und der Motor sollte ausgetauscht oder gewartet werden. Somit kann der Zeitpunkt der Wartung vorhergesagt werden.

Die Abbildung verdeutlicht die Vorhersage für eine neue Beobachtung.
Autoren, Tools und Quellen
Autor:
Prof. Dr. Eva Maria Kiss
Mit Beiträgen von:
M.Sc. Anke Welz
Quellen und weiterführende Links: