Python Tutorial – Der Einstieg mit Jupyter Notebook
Diese Tutorial-Reihe des elab2go bietet einen Einstieg in die Programmiersprache Python. Die grundlegende Syntax wird im ersten Teil vorgestellt (Variablen, Operatoren, Datenstrukturen, Verzweigungen und Schleifen, Funktionen, objektorientierte Programmierung mit Klassen). In Teil 2: Pakete installieren wird das Installieren und Verwenden von Paketen mittels der Paketverwaltungssysteme pip und conda erklärt. Teil 3: Python Bibliotheken gibt einen Einstieg in die wichtigsten Python-Bibliotheken für Wissenschaftliches Rechnen, Datenanalyse, und Machine Learning. Das Tutorial wird ergänzt durch Python-Quizzes zu unterschiedlichen Aspekten der Python-Programmierung.
Motivation
Python wird aktuell viel in KI-Anwendungen verwendet, häufig in Kombination mit der Plattform Anaconda (für Anwendungs- und Paketverwaltung) und Visual Studio Code oder Jupyter Notebook als Entwicklungsplattform. Die einfache Verwendung der kostenlosen Python-Programmpakete für Datenverwaltung, -Modellierung und -Analyse Numpy, Pandas, Scikit-Learn, Keras, Tensorflow, PyTorch machen Python zu einer attraktiven Alternative für Einsteiger.
Warum Python?
Python ist eine der meistgenutzten Programmiersprachen mit vielfachen Einsatzgebieten: 1. in der Grundausbildung als erste Programmiersprache, 2. in der Lehre an Hochschulen für die didaktische Aufbereitung und das Teilen von Demonstratoren und 3. im Umfeld des Machine Learning, wo Python einen großen Funktionsumfang und gleichzeitig einen einfachen Zugang bietet. Für die Verwendung von Python für Machine Learning und Datenanalyse sprechen eine Vielzahl von Gründen:
-
Python ist gut lesbar und verständlich, somit ist ein schneller Einstieg in die Syntax möglich.
-
Python bietet umfangreiche und kostenlose Programmbibliotheken für Datenverwaltung und Datenanalyse.
-
Python kann prozedural oder objektorientiert verwendet werden, ist multiplattform-fähig (Windows, Linux, Raspberry Pi usw.) und kann auch in eingebetteten Systemen eingesetzt werden.
Warum Jupyter Notebook?
Jupyter Notebook ist eine webbasierte Umgebung, die das Erstellen, Dokumentieren und Teilen von Demonstratoren unterstützt, und zwar insbesondere im Umfeld der Datenanalyse. In einem Jupyter Notebook kann man Code schreiben und ausführen, Daten visualisieren, und diesen Code auch mit anderen teilen. Das Besondere an Jupyter Notebook ist, dass der Code und die Beschreibung des Codes in unabhängige Zellen geschrieben werden, so dass einzelne Codeblöcke individuell ausgeführt werden können.
Übersicht
Das Tutorial ist in 12 Abschnitte gegliedert, die die Python-Syntax an einfachen Beispielen erklären und aufeinander aufbauen:
-
1 Vorbereitung: Installation der Entwicklungsumgebung
1-1 Jupyter Notebook
1-2 Visual Studio Code
1-3 Spyder - 2 Erste Codezeilen in Python
2-1 Hello World-Programm
2-2 Einrückungen in Python
2-3 Kommentare in Python - 3 Variablen und Datentypen
3-1 Datentypen
3-2 Numerische Datentypen
3-3 String-Datentypen
3-4 Boolesche Datentypen - 4 Operatoren und Ausdrücke
Arithmetisch Zuweisung Logik Vergleich Identität Mitgliedschaft - 5 Ein- und Ausgabe
input print - 6 Verzweigungen
if elif else match-case - 7 Schleifen
while for - 8 Datenstrukturen für Listen und Mengen
8-1 Listen
Index Iterator List Comprehension append, insert, remove join
8-2 Tupel
8-3 Mengen
8-4 Dictionaries - 9 Funktionen in Python
def return *args lambda
9-1 Selbstdefinierte Funktionen
9-2 Funktionen mit variabler Parameterliste
9-3 Lambda-Funktionen - 10 Klassen und Vererbung
oop class self init
10-1 Klassen in Python deklarieren
10-2 Vererbung in Python
10-3 UML-Klassendiagramme - 11 Fehlerbehandlung
11-1 Fehler mit try-except behandeln
11-2 Mehrfache Fehlerbehandlung
11-3 Fehler mit raise erzeugen - 12 Python vs. MATLAB, R, C
12-1 Python vs. MATLAB
12-2 Python vs. C
Das Tutorial ist als Google Colab Notebook online verfügbar:
1 Installation der Entwicklungsumgebung
Um Python-Programme schreiben zu können, muss zunächst eine aktuelle Python-Installation von der Python-Webseite python.org heruntergeladen und installiert werden. Für die Entwicklung größerer Programme und die Durchführung von Datenanalysen sollte zusätzlich die Data Science Plattform Anaconda mit den Entwicklungs- und Laufzeitumgebungen Spyder und Jupyter Notebook verwendet werden, die umfangreiche Funktionalität für Paketverwaltung, Softwareentwicklung und Präsentation bereitstellen. Bei der Installation von Anaconda werden die Paketverwaltungstools pip und conda gleich mit installiert, mit deren Hilfe man von der Kommandozeile aus weitere Python-Pakete verwalten kann.
Anaconda ist eine Entwicklungplattform für die Programmiersprachen Python und R, die für wissenschaftliches Rechnen und Machine Learning verwendet wird. Anaconda unterstützt insbesondere die Verwaltung von Anwendungen und Paketen, die nützlich bei der Programmierung mit Python und R sind. Zu den verfügbaren Anwendungen gehören Spyder (für Python-Entwicklung), RStudio (für R-Entwicklung), Jupyter Notebook und Jupyter Lab (für die Erstellung interaktiver Demos). Mit Hilfe der Paketverwaltung conda können Anwendungsumgebungen / Environments erstellt werden, in die jeweils zueinander passende Versionen der benötigten Pakete heruntergeladen werden.
Weitere Details der Installation von Python und Anaconda sind im Abschnitt Vorbereitung: Installation von Python und Anaconda beschrieben.
Bei der Entwicklung größerer Python-Projekte, wo Syntax-Highlighting, Debugging-Funktionalität etc. wichtig sind, können weitere Entwicklungsumgebungen wie Visual Studio Code und PyCharm verwendet werden. Für den Einstieg und für kleinere Datenanalyse-Projekte, ist Anaconda + Jupyter Notebook + Visual Studio Code eine gute Startkombination.
1-1 Jupyter Notebook
Die Verwendung von Jupyter Notebook für den Einstieg hat den Vorteil, dass der Aufwand für die Installation einer Entwicklungsumgebung entfällt und man sich auf die Syntax der Sprache konzentrieren kann. Ein dokumentiertes Jupyter Notebook, das die wichtigsten Sprachkonstrukte mit Beispielen enthält, kann einfach geteilt werden, z.B. über Google Colab. Die Beispiele werden in separate Codezellen gespeichert und können in beliebiger Reihenfolge ausgeführt werden. Der Nachteil ist, dass die fortgeschrittene Funktionalität einer Entwicklungsumgebung (Syntax-Highlighting, Auto-Vervollständigung, Debuggen) hier fehlen.
Vorbereitung: Anaconda und Jupyter Notebook installieren
Die Details der Installation von Python und Anaconda sind in dem Abschnitt Vorbereitung: Installation von Python und Anaconda beschrieben.
Die Details der Verwendung von Jupyter Notebook sind in den Abschnitten Jupyter Notebook verwenden und Jupyter Notebook Widgets verwenden beschrieben, zu denen es auch YouTube-Anleitungen gibt.
Video: Jupyter Notebook
Das folgende Video zeigt, wie ein Jupyter Notebook erstellt und verwendet wird.
1-2 Visual Studio Code
Visual Studio Code (kurz: VS Code) ist eine Entwicklungsumgebung von Microsoft, die plattformübergreifend unterschiedliche Programmiersprachen unterstützt, z.B. Python, PHP, oder Java, wobei die benötigte Unterstützung jeweils durch Erweiterungen dazu installiert wird.
Das Besondere an Visual Studio Code ist, dass es keine integrierte Entwicklungsumgebung mit fest eingebauter Funktionalität ist, sondern ein Gehäuse, in das man durch "Extensions" die Unterstützung für eine Vielzahl von Programmiersprachen hinzu installieren kann. Extensions werden über den Menüpunkt Extensions und das Tastenkürzel Ctrl + Shift + X angezeigt und darüber auch installiert. Für die Python-Programmierung muss die Python extension for Visual Studio Code installiert werden, sowie Python Debugger extension for Visual Studio Code.
Die Installation von VS Code kann entweder für einen einzelnen Benutzer erfolgen, oder als System-Installation für alle Benutzer eines Rechners. Die bevorzugte Art der Installation unter Windows ist die User-Installation, diese erfolgt in dem Benutzer-Ordner des Users und es werden keine Admin-Rechte benötigt.
Für die Python-Programmierung mit Visual Studio Code muss zunächst ein aktuelle Python-Interpreter von python.org
installiert werden. Anschließend installiert man die erforderlichen Python-Extensions:
(1) Python-Extension von Microsoft, für IntelliSense, Linting (Fehleranalyse im Code), Debugging
(2) Jupyter-Extension, für Jupyter Notebook-Unterstützung, um den Code in Codeblöcke strukturieren
und diese getrennt in der interaktiven Konsole ausführen zu können.
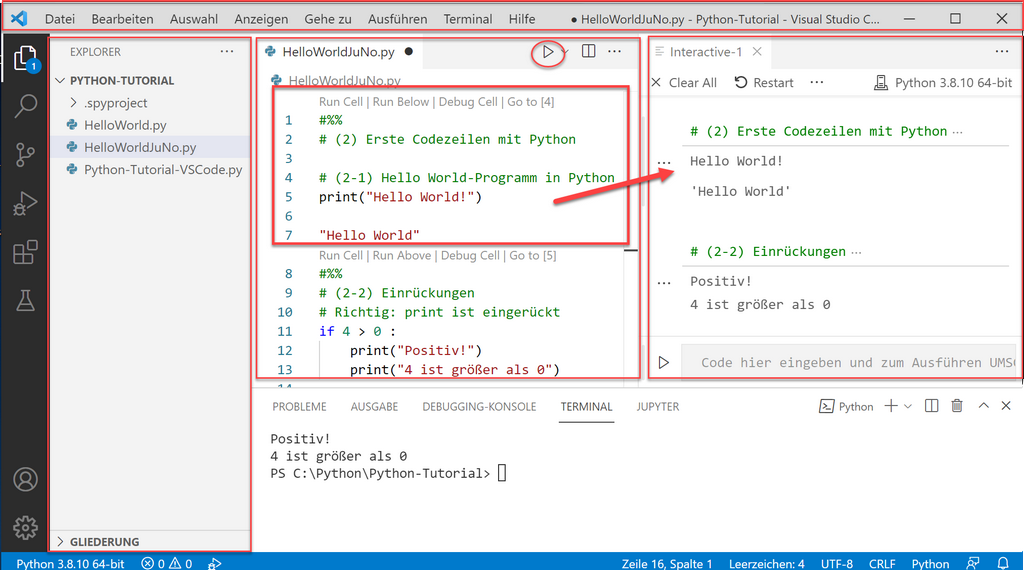
Die Benutzeroberfläche von Visual Studio Code ist in Menüleiste, Seitenleiste und drei Panels organisiert, die für die Entwicklung und Ausführung von Skripten verwendet werden. In der Seitenleiste hat man einen Schnellzugriff auf Explorer, Suche, Quellcodeverwaltung. Die Anordnung dieser Fenster kann über das Anzeigen-Menü angepasst werden.
- Explorer-Panel: zeigt die Ordner und Dateien an, die Python-Skripte enthalten. Hier werden neue Ordner und Skripte erstellt.
- Editor-Panel: enthält den Inhalt (Quellcode, Kommentare) einer Python-Datei und die Buttons zum Ausführen und Debuggen des Codes.
- Ausgabe-Panel: enthält verschieden Tabs für Probleme / Ausgabe / Debugging-Konsole / Terminal.
- Interaktive Jupyter-Konsole: hier wird die Ausgabe der ausgeführten Jupyter Codezellen angezeigt. Die interaktive Jupyter-Konsole ist nur sichtbar, wenn die Jupyter-Erweiterung installiert ist und das Skript mit #%% markierte Jupyter-Codezellen enthält.
Der Screenshot zeigt die Benutzeroberfläche von Visual Studio Code mit einem geöffneten Skript, das durch Angabe der speziellen Kommentare #%% den Code in Codezellen gliedert, die separat ausgeführt werden können. Die Entwicklung in Visual Studio Code ist ordnerbasiert, d.h. man legt einen Ordner an, und darin zusammengehörige Skripte.
1-3 Spyder
Spyder ist eine Entwicklungsumgebung für Python, die vor allem in Datenanalyse-Projekten eingesetzt wird. Die Entwicklung in Spyder ist projekt- oder ordnerbasiert, d.h. man kann mehrere Python-Skripte entweder in einem Projekt organisieren oder als lose Sammlung in einem Ordner.
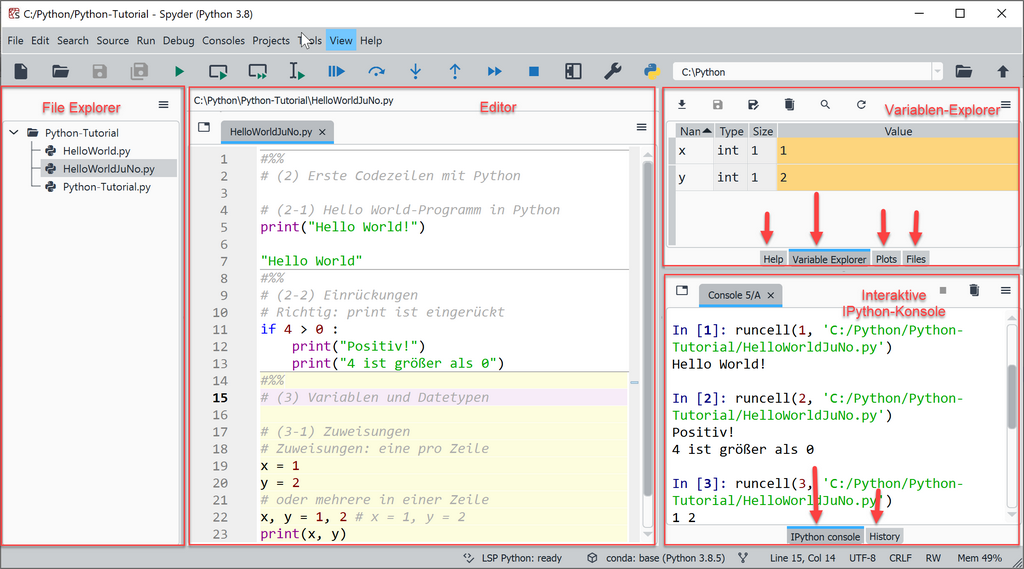
Die Benutzeroberfläche von Spyder ist in Menüleiste und drei Haupt-Panels (Editor, Interaktive Konsole, Variablen-Explorer) organisiert, die für die Entwicklung und Ausführung von Skripten verwendet werden. Weitere Panels (Files, Plots, Help) sind als Tabs in das Variablen-Explorer-Panel integriert. Die Anordnung dieser Fenster kann über das View-Menü angepasst werden.
- Editor-Panel: enthält den Inhalt (Quellcode, Kommentare) der Python-Skripte. Hier wird Python programmiert!
- Variablen-Explorer: dies Panel enthält die Tabs für die Anzeige der Variablen des ausgeführten Skripts. Weitere hier integrierte Tabs sind Plots (Anzeige der Plots), Help (Hilfe) und Files (Ordner und Dateien).
- IPython-Konsole: hier wird die Ausgabe der ausgeführten Jupyter Codezellen angezeigt.
- Files-Panel: zeigt die Ordner und Dateien an, die Python-Skripte enthalten. Hier werden neue Ordner und Skripte erstellt.
Der Screenshot zeigt die Benutzeroberfläche von Spyder mit einem geöffneten Skript, das durch Angabe der speziellen Kommentare #%% den Code in Codezellen gliedert, die separat ausgeführt werden können.
2 Erste Codezeilen in Python
Ein Python-Programm kann auf verschiedene Arten erstellt und getestet werden:
1. Interaktiver Modus: Der interaktive Modus erfolgt durch Eingabe der Python-Anweisungen in der Python-Befehlskonsole, dort erfolgt auch die Ausgabe.
Dies ist nützlich für Tutorials, und um Programmteile zu testen. Um die Python-Befehlskonsole aufzurufen,
unter Programme das Programm mit dem Namen Python auswählen.
2. Python-Skript: Größere Python-Programme sind Sammlungen von Python-Skripten, die sich in demselben Ordner befinden und
ein Programmpaket bilden.
Ein Python-Skript oder Python-Modul ist dabei eine Datei mit der Endung .py, das die Anweisungen des Programms enthält und
mit Hilfe von Funktionen und Klassen strukturiert werden kann.
Wichtig: damit ein Verzeichnis zum Python-Paket wird, muss es eine Datei mit dem Namen __init.py__ enthalten, die leer sein kann.
3. Jupyter Notebook: Für Tutorials oder interaktive Demos erstellen wir ein Jupyter Notebook,
das die einzelnen Python-Anweisungen in Zellen strukturiert, die getrennt voneinander dokumentiert und ausgeführt werden können.
Im Unterschied zum interaktiven Modus der Python-Befehlskonsole können Jupyter Notebooks besser für Demos, Lehre und Kollaboration verwendet werden.
Im Folgenden verwenden wir zunächst den interaktiven Modus, d.h. die Befehle werden direkt in der Python-Konsole eingegeben.
Um die Python-Befehlskonsole mit einer bestimmten Python-Version zu öffnen, wird Anaconda aufgerufen und das entsprechende Environment ausgewählt.
Durch Anklicken des Environments erhält man verschiedene Anwendungen zur Auswahl: Open Terminal, Open with IPython, Open with Jupyter Notebook.
Durch Auswahl des Menüpunktes "Open with Python" wird die Python Befehlskonsole geöffnet, dort werden die Python-Befehle direkt eingegeben
und es erfolgt dort auch die Ausgabe.
2-1 Hello World-Programm
Das Hello-World-Programm ist das kleinste lauffähige Programm in Python und gibt den Text "Hello World" auf der Konsole aus. Es verwendet für die Ausgabe die print-Funktion, die als Parameter die Zeichenkette "Hello World" erhält.
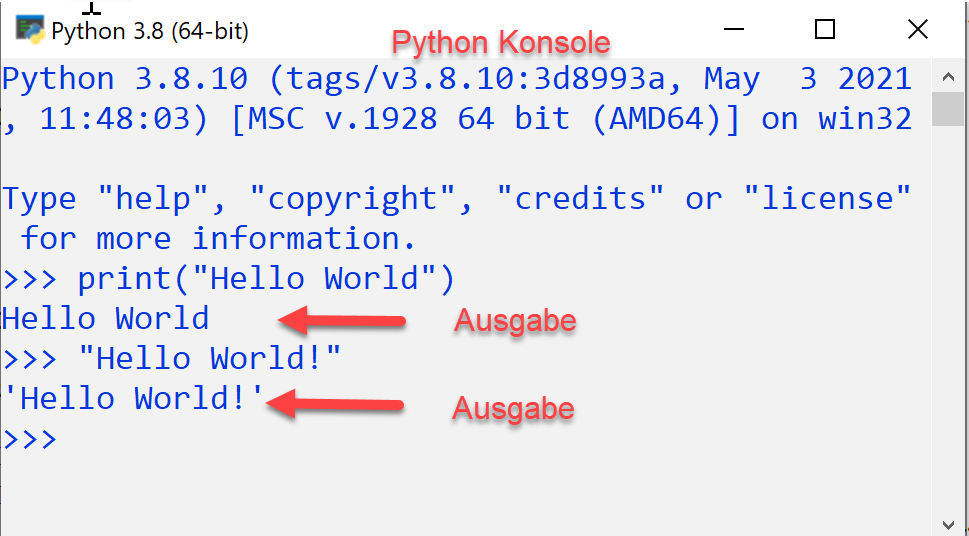
Für die Entwicklung größerer Programme werden die Python-Befehle mit Hilfe einer Entwicklungsumgebung in ein Python-Skript gespeichert, d.h. in eine Datei mit der Endung *.py, die alle Befehle und Funktionen des Programms enthält.
helloworld.py
print('Hello World')
Python-Programme erfordern im Unterschied zu C, C++ oder Java nicht zwingend eine main-Funktion als Einstiegspunkt. Bei größeren Python-Projekten ist es allerdings üblich, eine main-Funktion zu verwenden, in folgender Form:
main.py - mit main-Funktion als Einstiegspunktdef main():# Hier werden weitere Funktionen aufgerufenprint('Hello World')# Einstiegspunkt der Anwendungif __name__ == "__main__":main()
2-2 Einrückungen in Python
Python verwendet Einrückungen und Leerzeichen, um Codeblöcke zu definieren, d.h. zusammengehörige Befehle anzugeben. Dies ist ein signifikanter Unterschied zu Programmiersprachen wie C oder Java, bei denen die Einrückung (engl. Indentation) im Code nur der Lesbarkeit dient und Leerzeichen vom Compiler / Interpreter ignoriert werden.
Python-Code: Richtige EinrückungPython-Code: Falsche Einrückung# Richtig: eingerücktif 4 > 0 :print("Positiv!")print("4 ist größer als 0")
# Falsch: nicht eingerücktif 4 > 0 :print("4 ist größer als 0")

Der erste Code "Richtige Einrückung" wird ausgeführt, beim zweiten Code "Falsche Einrückung" wird eine Fehlermeldung ausgegeben, da die print-Anweisung nicht eingerückt ist. Falls wir in Zeile 4 des ersten Codes vor der print-Anweisung ein Leerzeichen einfügen, wird auch hier ein Fehler auftreten ("IndentationError: unexpected indent"), da jede Anweisung des if-Codeblocks um dieselbe Anzahl an Stellen eingerückt werden muss.
Die korrekte Einrückung ist wichtig, sobald man mit mehrzeiligen Anweisungen, d.h. Verzweigungen, Schleifen und Funktionen arbeitet, die auch mehrzeilige Codeblöcke umschließen. Für die automatische Korrektur der Einrückung kann man Programmpakete wie autopep3 verwenden, die in alle Entwicklungsumgebungen eingebunden werden können.
2-3 Kommentare in Python
Python verwendet unterschiedliche Arten von Kommentaren für die Dokumentation des Codes. Kommentare werden nicht vom System ausgeführt, sondern dienen der besseren Lesbarkeit und Verständlichkeit von Quellcode. Einzeilige Kommentare beginnen mit einem "#"-Symbol, gefolgt von Text. Mehrzeilige Kommentare müssen am Anfang und Ende von je drei doppelten Anführungsstrichen eingerahmt werden.
Python-Code: Kommentare# Einzeiliger Kommentar# Noch ein Kommentar"""MehrzeiligerKommentar"""
Kommentare sind besonders wichtig, sobald größere Programme mit Funktionen und Klassen entwickelt werden.
Bei der Verwendung von Funktionen sollte eine Kurzbeschreibung der Funktion, der Funktions-Parameter
und des Rückgabewertes angegeben werden.
Dies geschieht, indem die Kommentare in die oben erwähnten drei doppelten Anführungsstrichen nach der Funktionssignatur geschrieben werden.
Tut man dies, so wird bei Aufruf des Befehls help(funktionsname) der zuvor angegebene Funktionskommentar als Hilfe ausgegeben.
Für die Erstellung professioneller Dokumentation im HTML- oder PDF-Format kann ein Dokumentations-Tool
wie Doxygen eingesetzt werden.
Doxygen bietet eine spezielle Syntax für Kommentare, und kann aus den Kommentaren eine Dokumentation im HTML-Format zu erzeugen.
Beispiel: Funktion in Doxygen-Syntax kommentieren
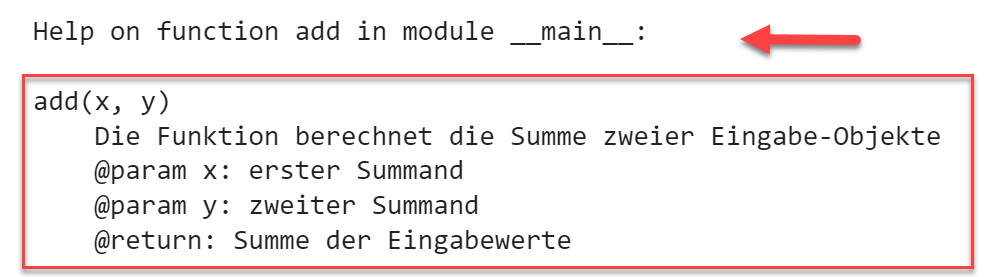
In dem folgenden Beispiel werden Wirkung und Parameter der Funktion add(x, y) kommentiert.
Ausgabedef add(x, y):"""Die Funktion berechnet die Summe zweier Eingabe-Objekte@param x: erster Summand@param y: zweiter Summand@return: Summe der Eingabewerte"""return x + yhelp(add)
3 Variablen und Datentypen
Variablen sind benannte Speicherplätze, in denen die Daten des Programms gespeichert werden, z.B. name, jahr, x, y. Python-Variablen werden deklariert, sobald man ihnen einen Wert zuweist, z.B. x = 1, name = "HS KL". Der Datentyp (ganze Zahl, Fließkommazahl, Zeichenkette etc.) der Variablen wird automatisch durch Python vergeben und kann mit Hilfe der type-Anweisung herausgefunden werden.
Python-Code: Variablen und print-FunktionPython-Code: type-Funktion# name hat den Datentyp Stringname = "HS KL"# jahr hat den Datentyp Integerjahr = 2022# Zuweisungen: eine pro Zeilex = 1y = 2# oder mehrere in einer Zeilex, y = 1, 2 # x = 1, y = 2# Ausgabe der Variablenprint(name, "\n", jahr, "\n", x, y)
# isPositiv wird als Wahrheitswert ausgewertetisPositiv = (x > 0)# Klasse herausfindenprint(isPositiv, " hat den Datentyp ", type(isPositiv))
3-1 Datentypen
Python hat einfache Datentypen für ganze Zahlen, Fließkommazahlen, Wahrheitswerte , Zeichen und Zeichenketten, darüber hinaus Datenstrukturen für Listen, Mengen und Schlüssel-Wert-Paare, wie folgt:
- Numerische Datentypen: int, float, complex
- Für ganzahlige Werte, Fließkommazahlen, komplexe Zahlen
- Boolesche Datentypen: bool
- Für Wahrheitswerte, True oder False
- Zeichenketten: str
- Für Texte
- Binäre Datentypen: bytes, bytearray, memoryview
- Listen: list, tuple, range
- Speichern Sequenzen aus Werten und Objekten
- Mappings: dictionary
- Speichern Schlüssel-Wert-Paare
- Mengen: set, frozenset
- Speichern ungeordnete Mengen
- Mehrdimensionale Arrays für statistische Berechnungen
- über die Bibliothek NumPy
- DataFrames für tabellarisch angeordnete Daten
- über die Bibliothek Pandas
Weiterhin gibt es das None-Objekt, dies gehört zu keinem Datentyp sondern wird verwendet, um Variablen / Objekte mit "Nichts" zu initialisieren bzw. zu prüfen, ob sie einen verfügbaren Wert haben. Der Datentyp einer Variablen wird meist implizit bei Zuweisung eines Wertes festgelegt, er kann jedoch bei Bedarf auch explizit durch Typecasting angegeben werden, indem man den gewünschten Datentyp vor den Namen des Wertes schreibt und diesen in runde Klammern setzt, z.B. x = float(5) oder x = str("Hallo!").
Python-Code: Typumwandlung# Datentyp von x# ist implizit intx = 5print(type(x)) # Ausgabe: class'int'# Datentyp von x# wird auf float festgelegtx = float(5)print(type(x)) # Ausgabe: class'float'
3-2 Numerische Datentypen
Es gibt in Python drei Hauptdatentypen für Zahlen: int (ganze Zahlen), float (Fließkommazahlen) und complex (komplexe Zahlen), sowie einen Datentyp Decimal für korrekt gerundete Fließpunktarithmetik. Der in Python eingebaute Datentyp float hat doppelte Genauigkeit und entspricht dem Datentyp double in C oder Java.
Python-Code: Numerische Datentypenx = 5 # intpi = 3.14 # float# Komplexe Zahl z = 2 + 3 iz = complex(2, 3)# Typecastingx = int(pi) # x = 3z = int("3") # z = 3
3-3 String-Datentypen
Der Datentyp String beschreibt Texte bzw. Zeichenketten.
Die Position eines Zeichens in einer Zeichenkette wird durch Angabe eines Index angegeben, der bei 0 anfängt.
Es können auch negative Indizes verwendet werden, dann wird die Zeichenkette vom Ende durchlaufen.
Für eine Zeichenkette x erhält man mit x[0] das erste Element, mit x[-1] das letzte Element,
mit x[i:j] die Zeichen von i inklusive bis j exklusiv.
Um Zeichenketten zu bearbeiten, verwendet man eine Reihe von Funktionen, wie len(), format(), encode(), strip(), und viele mehr. Mit der Funktion len(x) wird die Länge einer Zeichenkette nachgefragt, also die Anzahl an Zeichen in dieser Kette. Mit der x.strip()-Anweisung besteht die Möglichkeit, Leerzeichen am Anfang und am Ende einer Zeichenkette zu löschen.
Python-Code: Zeichenkettenx = "Hallo!"print(x[0]) # Hprint(x[-1]) # !print(x[1:6]) # allo!print(x[-4:-1]) # lloprint(len(x)) # 6x = " Hallo aus Kaiserslautern "print(x.strip())
String-Präfixe
Um die die Interpretation von Python-Strings zu steuern, verwendet man die String-Präfixe
f, r oder b.
- Stellt man einem String den Präfix f voran, wird der String als formatierter String interpretiert und kann Ausdrücke enthalten, die in geschweifte Klammern gesetzt werden.
- Stellt man einem String den Präfix r voran, wird der String als "raw" interpretiert, dann werden Steuerzeichen wie z.B. der Rückschrägstrich als gewöhnliche Zeichen behandelt. In diesem Fall darf der String keine Ausdrücke enthalten. Raw-Strings sind dann nützlich, wenn man Pfadangaben für Dateien erstellt, da der Backslash hier als normales Zeichen interpretiert werden soll und nicht als Steuerzeichen.
- Stellt man einem String den Präfix b voran, wird er als ein Byte-Array behandelt. Diese Art von Strings wird häufig in der Kryptografie benötigt. Um z.B. Texte mit der AES-Verschlüsselung zu verschlüsseln, müssen sie zunächst in Byte-Arrays umgewandelt werden.
Python-Code: String-Präfixe In diesem Beispiel werden drei Strings erstellt: str_formatted, str_raw und str_bytes. Wir geben sowohl die Strings selber als auch den Typ (also die Klasse) der Strings aus.
import datetimestr_formatted = f'Jetzt ist {datetime.datetime.now()}'print(str_formatted)print(type(str_formatted))str_raw = r'C:\Temp'print(str_raw)print(type(str_raw))str_bytes = b'H\x65llo'print(str_bytes)print(type(str_bytes))
Ausgabe: String-Präfixe Bei der Ausgabe sieht man, dass str_formatted und str_raw den Typ str haben, str_bytes hat jedoch den Datentyp bytes.
Jetzt ist 2025-06-27 17:08:30.937031 <class 'str'> C:\Temp <class 'str'> b'Hello' <class 'bytes'>
3-4 Boolesche Datentypen
Boolesche Datentypen können nur zwei Werte annehmen, wahr oder falsch. In Python wird jede Zahl außer "0" als wahr, engl. "True", betrachtet und "0" wird als falsch, engl. "False", interpretiert. Generell wird jeder Wert mit Wahr bewertet, wenn er einen Inhalt enthält, egal ob String, Integer oder List. Boolesche Datentypen werden benötigt, wenn man auswerten muss, ob ein Ausdruck wahr oder falsch ist, zum Beispiel, wenn die Bedingung einer bedingten Verzweigung oder Schleife ausgewertet wird.
print(6 > 5) # Trueprint(6 == 4) # False
4 Operatoren
Mit Operatoren werden Berechnungen an Variablen und Werten ausgeführt und das Ergebnis wird einer neuen Variablen zugewiesen. Um den Abstand dist zwischen zwei Punkten (x1, y1) = (10, 2) und (x2, y2) = (4, 1) zu berechnen, wird in Zeile 3 ein Ausdruck mit Hilfe von Operatoren erstellt und einer neuen Variablen dist zugewiesen.
import mathx1, y1, x2, y2 = 10, 2, 4, 1dist = math.sqrt((x2 - x1)**2 + (y2 - y1)**2)print("Abstand", dist) # Ausgabe: 6.08
Hier werden vier Operatoren verwendet: der Zuweisungsoperator =, die arithmetischen Operatoren +, - und der Potenzierungs-Operator **, sowie die math.sqrt-Funktion, um die Quadratwurzel zu berechnen. Bei der Auswertung von Ausdrücken wird eine festgelegte Priorität der Operatoren beachtet, z.B. hat Multiplikation eine höhere Priorität als Addition, in dem Ausdruck 2 * x + 1 wird zuerst x mit 2 multipliziert und dann 1 hinzuaddiert. Um die Ausführungsreihenfolge bei größeren Ausdrücken zu steuern, werden runde Klammern verwendet, was in den Klammern steht, wird zuerst ausgeführt. Python unterteilt die Operatoren in folgende Gruppen:
- Arithmetische Operatoren: +, -, *, /, //, %, **
Arithmetische Operatoren führen die bekannten mathematischen Operationen aus. Außer den Grundoperationen gibt es noch die Ganzzahldivision, den Modulo-Operator und die Potenzierung. - Zuweisungsperatoren: =, +=, -=, *=, /=, //=, %=
Zuweisungsoperatoren weisen Variablen Werte zu. Python verwendet für alle arithmetischen Operatoren die abkürzende Zuweisung, es gibt jedoch keine Inkrementierung oder Dekrementierung wie in C-ähnlichen Sprachen. - Vergleichsoperatoren: ==, !=,<, >, <=, >=
Vergleichsoperatoren vergleichen zwei Werte und liefern wahr oder falsch als Ergebnis. Zum Beispiel testet a == b ob a gleich b ist, und liefert je nachdem wahr oder falsch zurück, und a != b testet, ob a ungleich b ist. - Logische Operatoren: and, or, not
Logische Operatoren kombinieren boolesche Ausdrücke, die dann als wahr oder falsch ausgewertet werden. Z.B. wird hier die Variable is_teenager = (alter > 13) and (alter < 19) als wahr ausgewertet, wenn der Wert der Variablen alter gleich 14 ist. - Identitätsoperatoren:
is, is not
Identitätsoperatoren vergleichen Objekte. Falls z.B. x = [1, 2, 3] gilt, also x eine Liste ist, dann liefert type(x) is list wahr, und type(x) is not list ist falsch. - Mitgliedsoperatoren: in, not in
Mitgliedsoperatoren prüfen, ob ein Objekt Mitglied einer Liste ist, z.B. prüft 4 in [1,2,3], ob 4 in der Liste enthalten ist. - Bitweise Operatoren: &, ^, |, >>, <<
Bitweise Operatoren führen eine bitweise Verknüpfung der Operanden aus.
Die meisten Python-Operatoren sind identisch mit den gleichnamigen Operatoren in C oder Java, mit einigen Besonderheiten bei Ganzzahldivision und Potenzierung oder den Mitglieds-Operatoren in, not in, is, is not.
Übersicht der Operatoren
Arithmetische Operatoren werden mit numerischen Werten verwendet,
um allgemeine mathematische Operationen auszuführen.
| Operator | Beispiel | Wirkung |
|---|---|---|
| Addition | x + y | 10 + 3 # Ergebnis: 13 |
| Subtraktion | x - y | 10 - 3 # Ergebnis: 7 |
| Multiplikation | x * y | 10 * 3 # Ergebnis: 30 |
| Division | x / y | 10 / 3 # Ergebnis: 3.33 |
| Ganzzahl-Division | x // y | 10 // 3 # Ergebnis: 3 |
| Modulo-Operator | x % y | 10 % 3 # Ergebnis: 1 |
| Potenzierung | x ** y | 10 ** 3 # Ergebnis: 1000 |
Zuweisungsoperatoren werden verwendet, um Variablen Werte zuzuweisen.
Bei der Zuweisung x = y wird der Wert der Variablen y (rechte Seite) der Variablen x (linke Seite) zugewiesen.
Bei abkürzenden Zuweisungen wird jeweils eine Operation auf dem Wert einer Variablen ausgeführt und dieser neue
Wert erneut der Variablen zugewiesen.
| Operator | Beispiel | Wirkung |
|---|---|---|
| Zuweisung | x = y | Variable x erhält den Wert y |
| Abkürzende Addition | x += 4 | x = x + 4 # Der Wert der Variablen x wird um 4 erhöht |
| Abkürzende Multiplikation | x *= 4 | x = x * 4 |
| Abkürzende Division | x /= 4 | x = x / 4 |
| Abkürzende Ganzzahl-Division | x //= 4 | x = x // 4 |
| Abkürzende Modulo | x %= 4 | x = x % 4 |
Vergleichsoperatoren und logische Operatoren werden zusammen verwendet, um Bedingungen zu formulieren, d.h. Ausdrücke, die als wahr oder falsch ausgewertet werden.
Vergleichsoperatoren verknüpfen zwei Variablen / Werte, und das Ergebnis wird als wahr oder falsch ausgewertet.
| Operator | Beispiel | Wirkung |
|---|---|---|
| Gleich | x == y | wahr, wenn x gleich y ist |
| Ungleich | x != y | wahr, wenn x ungleich y ist |
| Größer | x > y | wahr, wenn x größer als y ist |
| Kleiner | x < y | wahr, wenn x kleiner als y ist |
| Größer gleich | x >= y | wahr, wenn x größer gleich y ist |
| Kleiner gleich | x <= y | wahr, wenn x kleiner gleich y ist |
Logische Operatoren werden verwendet, um boolesche Ausdrücke zu kombinieren.
P und Q stehen für logische Ausdrücke, z.B. P = (x > 10) und Q = (x < 20).
| Operator | Beispiel | Wirkung |
|---|---|---|
| Logisches Und | P and Q | Gibt wahr (1) zurück, wenn die Ausdrücke P und Q beide wahr sind |
| Logisches Oder | P or Q | Gibt wahr (1) zurück, wenn einer der Ausdrücke P oder Q wahr ist |
| Logische Verneinung | not P | Verneint den Ausdruck P: aus wahr wird falsch, aus falsch wird wahr |
Mitgliedsoperatoren prüfen die Zugehörigkeit eines Objektes zu einer Auflistung.
x steht hier für ein beliebiges Objekt, list für eine Auflistung.
| Operator | Beispiel | Wirkung |
|---|---|---|
| enthalten in | x in list | wahr, wenn x in der Liste list enthalten ist. |
| nicht enthalten | x not in list | wahr, wenn x nicht in der Liste list enthalten ist. |
Identitätsoperatoren prüfen, ob zwei Objekte auf denselben Speicherbereich zeigen.
x is y gibt wahr zurück, wenn beide Variablen dasselbe Objekt sind, d.h. auf denselben Speicherbereich zeigen.
| Operator | Beispiel | Wirkung |
|---|---|---|
| Gleich | x is y | wahr, wenn beide Variablen dasselbe Objekt sind |
| Nicht gleich | x is not y | wahr, wenn die Variablen nicht dasselbe Objekt sind |
Bitweise Operatoren (bitweises und, oder etc.) führen bitweise Operationen auf ganzzahligen Operanden aus.
D.h. die Operanden werden in ihre bitweise Darstellung konvertiert, z.B. x = 5 = 0101, y = 3 = 0011, und dann wird jedes
Bit im Operanden x mit dem Bit an der passenden Position im Operanden y verknüpft.
| Operator | Beispiel | Wirkung |
|---|---|---|
| Bitweises Und | x & y | Ergebnisbit ist 1, wenn beide Bits 1 sind |
| Bitweises Oder | x | y | Ergebnisbit ist 1, wenn mindestens eines der Bits 1 ist |
| Bitweises Entweder-Oder (XOR) | x ^ y | Ergebnisbit ist 1, wenn genau eines der Bits 1 ist |
| Bitweises Nicht | ˜ x | Gibt das Einerkomplement von x zurück |
| Shift-right | x >> n | Bits in x werden um n Positionen nach rechts geschoben. |
| Shift-left | x << n | Bits in x werden um n Positionen nach links geschoben. |
Beispiel
x = 5 # binär: 0101y = 3 # binär: 0011print("x & y = %d" % (x & y)) # 0101 & 0011 = 0001 (1)print("x | y = %d" % (x | y)) # 0101 | 0011 = 0111 (7)print("x ^ y = %d" % (x ^ y)) # 0101 ^ 0011 = 0110 (6)
5 Ein- und Ausgabe
Die Eingabe über die Konsole erfolgt mit Hilfe der input()-Funktion, für die Ausgabe wird die print-Funktion verwendet.
5-1 Eingabe mit input()
Die Eingabe über die Python-Befehlskonsole oder in einer Jupyter Notebook-Zelle erfolgt mit Hilfe der input()-Funktion. Der Befehl x = input() erzeugt ein Eingabefeld, und was man darin eingibt, wird in die Variable x gespeichert. Soll die Eingabe als ein bestimmter Datentyp interpretiert werden, muss sie mit Hilfe einer entsprechenden Funktion, z.B. int() oder float() umgewandelt werden.
Beispiel: Im folgenden Beispiel werden Eingaben unterschiedlichen Datentyps eingelesen und zur Kontrolle formatiert wieder ausgegeben.
Python-Code: Ein- und Ausgabe# Eingabe einer Zeichenketteprint("Text eingeben: "); text=input();# Eingabe einer ganzen Zahlprint("Ganze Zahl eingeben:"); x = int(input())# Eingabe einer Fließkommazahlprint("Kommazahl eingeben:"); y = float(input())print("Ihre Eingabe: Text= %s, x = %d, y = %f" % (text, x, y))
Die Ausgabe nach Ausführung der Zeilen 1 bis 5 dieses Codeblocks sieht aus wie unten abgebildet.
Mit Hilfe der input()-Funktion wird ein Eingabefenster erzeugt, das eine Eingabe erfordert.
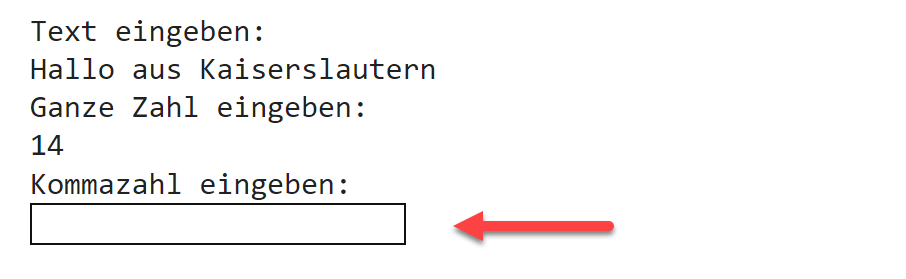
Die Funktion input() kann auch einen Aufforderungs-Text als Parameter erhalten, wie im nächsten Beispiel. Dann entfällt die separate Eingabeaufforderung per print und die Eingabeaufforderung steht in derselben Zeile wie der einzugebende Wert.
# Eingabe einer Zeichenkettetext = input("Text eingeben: ")# Eingabe einer ganzen Zahlx = int(input("Ganze Zahl eingeben: "))# Eingabe einer Fließkommazahly = float(input("Kommazahl eingeben: "))# Formatierte Ausgabeprint("Ihre Eingabe: Text= %s, x = %d, y = %f" % (text, x, y))

5-2 Ausgabe auf die Konsole
Es gibt zwei Wege, um den Inhalt einer Variablen in Python unformatiert in die Konsole / Standardausgabe auszugeben.
- Schreibe den Namen der Variablen in eine neue Zeile, ohne abschließendes Semikolon. Es wird stets nur die letzte Variable in einem Block ausgegeben! D.h. im Beispiel unten nur der Inhalt der Variablen y.
- Verwende print()-Funktion. Diese Funktion akzeptiert als Argument eine Zeichenkette, Variable, ein Objekt oder eine Liste von Objekten, es können auch Separatoren angegeben werden. Anders als in C muss defaultmäßig kein Sonderzeichen angegeben werden, um einen Zeilenumbruch zu erzeugen. Falls man jedoch ein print ohne Zeilenumbruch haben möchte, muss der print-Aufruf in der folgenden Form erfolgen: print("Hallo", end=','), d.h. mit Hilfe des Parameters end wird ein anderes Trennzeichen als der Zeilenumbruch festgelegt.
Variablenname in eine neue Zeile schreiben
x = 10y = 20xy
Ausgabe unterschiedlicher Variablen mit print
Ausgabeprint("Hallo")pi = 3.14print(pi)x, y = 10, 20print(x, y)print("x:", x, "y:", y)

5-3 Formatierte Ausgabe mit print() und format()
Formatierte Ausgaben, die Texte und die Inhalte von Variablen kombinieren, können in Python auf verschiedene Arten umgesetzt werden:
- (1) Verwendung von print mit str
Die Inhalte numerischer Variablen werden mit Hilfe der str- Funktion in Zeichenketten umgewandelt, mit Hilfe des +-Operators aneinandergefügt und dann mit print ausgegeben. - (2) Formatierte Ausgabe mit print und Platzhaltern (ähnlich wie in C)
Die Inhalte numerischer Variablen werden mit Hilfe von Platzhaltern in eine formatierende Zeichenkette eingefügt. Die formatierende Zeichenkette, z.B. "x=%d, y=%.1f, Summe=%.2f" enthält für jede Variable einen Platzhalter: %d - für ganze Zahlen, %.1f - für Fließkommazahlen mit einfacher Genauigkeit, gerundet auf eine Nachkommastelle, und %.2f - für Fließkommazahlen mit doppelter Genauigkeit, gerundet auf zwei Nachkommastellen. - (3) Formatierte Ausgabe mit print und format
Die String-Methode format setzt in eine formatierende Zeichenkette an die Stelle von Platzhaltern die Inhalte der Variablen ein, die ihr als Parameter übergeben werden.
Das folgende Beispiel erzeugt drei Mal (fast) dieselbe Ausgabe:
Ausgabe# Ausgabe: x=5, y=20.5, Summe=25.50x, y = 5, 20.5sum = x + y# (1) Ausgabe eines Textes mit angefügter float-Variablenprint("x=" + str(x) + " y=" + str(y) + " Summe=" + str(sum))# (2) Formatierte Ausgabe mit Platzhaltern (C-Style)print("x=%d, y=%.1f, Summe=%.2f" % (x, y, x + y))# (3) Formatierte Ausgabe mit formatprint("x={0:d}, y={1:.1f}, Summe={2:.2f}".format(x, y, x+y))

6 Verzweigungen
Eine Verzweigung ist eine Kontrollstruktur, die festlegt, welcher von zwei (oder mehr) Anweisungsblöcken,
abhängig von einer (oder mehreren) Bedingungen, ausgeführt wird.
Verzweigungen werden in Python wie in fast allen Programmiersprachen mit der if-Anweisung beschrieben.
Das Schlüsselwort elif in Python ist genau wie: "Wenn die vorherigen Bedingungen nicht zutreffen, versuch es mit dieser Bedingung" und das Schlüsselwort
else fängt alles ab, was von den vorhergehenden Bedingungen nicht erfasst wird.
x, y = 1, 4 # x = 1 und y = 4if x > y :print("%d > %d" % (x, y))elif x == y :print("%d == %d" % (x, y))else :print("%d < %d" % (x, y))
Komplexere Bedingungen werden mit Hilfe von Vergleichsoperatoren und logischer Operatoren formuliert.
Neuere Python-Versionen (ab Python 3.10) unterstützen auch eine match-case-Anweisung, die der switch-Anweisung in C und Java ähnelt, jedoch eine erweiterte Funktionalität zum Filtern von Mustern enthält. In dem folgenden Beispiel wird eine Funktion auswahl() definiert, die mittels match-case bei den Werten 1, 2, oder 3 für den Parameter nr den jeweils passenden Text, und bei allen anderen Werten für nr eine Fehlermeldung ausgibt.
Python-Code: match-case-Anweisungdef auswahl(nr):match nr:case 1:print("Erste Wahl")case 2:print("Zweite Wahl")case 3:print("Dritte Wahl")case _:print("Fehler: Ungültige Wahl")auswahl(1) # Erste Wahlauswahl(2) # Zweite Wahlauswahl(3) # Dritte Wahlauswahl(4) # Ungültige Wahl
7 Schleifen
Schleifen ermöglichen es, Anweisungen wiederholt auszuführen, und zwar so lange, wie eine Ausführungsbedingung erfüllt ist.
Python verfügt über zwei Schleifenbefehle: "while"-Schleife und "for"-Schleife.
Um den Kontrollfluss in Schleifen zu steuern, werden zusätzlich zu der Ausführungsbedingung die Anweisungen break
und continue eingesetzt.
break ermöglicht es, jederzeit aus einer Schleife auszusteigen. continue ermöglicht es, einzelne Schleifenschritte auszusetzen.
7-1 While-Schleife
Mit der while-Schleife werden Anweisungen ausgeführt, solange eine Bedingung wahr ist.
Beispiel: Berechne Summe 1+2+3+4+5 mit while-Schleife
Dieses Beispiel zeigt, wie eine Schleife unter Verwendung einer Zählvariablen geschrieben wird.
- Zeile 2: Initialisiere Zählvariable i mit 1
- Zeile 3: Prüfe Ausführungsbedingung i ≤ 5. Solange die Bedingung wahr ist, werden die Anweisungen des Schleifenrumpfs ausgeführt.
- Zeile 4-6: Diese Zeilen enthalten die Anweisungen des Schleifenrumpfs, die zu wiederholen sind. Wichtig: Die Zugehörigkeit zum Schleifenblock wird durch die korrekte Einrückung sichergestellt.
- Zeile 7: Ausgabe der Summe
sum = 0i = 1while i <= 5:print(str(i) + "+") # Ausgabe der Zählvariablensum += i # Addiere i zur Variable sum hinzui += 1 # Inkrementiere iprint("Summe = " + str(sum))
Die Ausgabe nach Ausführung dieses Codeblocks sieht aus wie abgebildet.
Die Anweisungen im Schleifenrumpf erzeugen die Ausgabe der zu addierenden Terme, die
print-Anweisung nach der Schleife (Zeile 7) erzeugt die Ausgabe der Gesamtsumme.

7-2 For-Schleife
Mit der for-Schleife iteriert man über die Elemente einer Sequenz (Liste, Tupel, Menge etc.). Die Syntax der for-Schleife erfordert zwingend, dass mit Hilfe des Mitgliedsoperators "in" über die Elemente einer Sequenz iteriert werden muss.
Beispiel 1: Gebe Elemente einer Studierenden-Liste aus
Die Iteration über die Elemente einer Listen-Datenstruktur ist in Python die bevorzugte Art, Schleifen zu verwenden.
Hierbei wird mit Hilfe des Mitgliedsoperators "in" die Mitgliedschaft eines Objektes zu einer Liste überprüft.
studenten = ["Max Muster", "Anna Test", "John Doe"]for std in studenten:print("Student: " + std)
Beispiel 2: Berechne Summe 1+2+3+4+5 mit for-Schleife
- Zeile 1: Initialisiere Variable sum mit 0
- Zeile 2: Iteriere mit der Zählvariablen i über die Sequenz {1,2,3,4,5}, die mit Hilfe des Funktionsaufrufs range(1,6) erzeugt wird.
- Zeile 3-4: Diese Zeilen enthalten die Anweisungen des Schleifenrumpfs
- Zeile 5: Ausgabe der Summe
sum = 0for i in range(1,6):print(str(i) + "+")sum += iprint("Summe = " + str(sum))
8 Datenstrukturen
In der Python Standardbibliothek gibt es Datenstrukturen für Listen, Mengen und Schlüssel-Wert-Paare: Listen (engl. lists), Tupel (engl. tuples), Mengen (engl. sets) und Dictionary (engl. dictionary). Die angeführten Python-Datenstrukturen unterscheiden sich darin, ob sie änderbar sind (oder nicht), geordnet sind (oder nicht), und Duplikate zulassen (oder nicht). Z.B. sind Listen änderbar, geordnet, und lassen Duplikate zu, Mengen hingegen sind änderbar, ungeordnet und lassen keine Duplikate zu. Python-Datenstrukturen können grundsätzlich Objekte beliebigen Datentyps enthalten. Jedoch sollte man bei der Durchführung von Operationen auf Elementen der Datenstruktur auf Kompatibilität achten. Der Zugriff auf die Elemente erfolgt über Iteratoren, bei Listen und Tupeln auch über einen Index, der bei 0 anfängt und die Position des Elementes in der Liste angibt.
8-1 Listen
Listen (engl. lists) sind Sammlungen von Objekten beliebigen Datentyps, die geordnet und änderbar sind. Sie erlauben doppelte Mitglieder und werden mit rechteckigen Klammern definiert. Listenelemente können wie im Beispiel unten über einen Index ausgewählt werden, der die Position des Elementes in der Liste angibt, oder man kann einen Iterator verwenden, um die Liste zu durchlaufen.
Beispiel: Studierende-Liste
Eine Python-Programm verwaltet eine Liste der Studierenden einer Hochschule.
Index verwenden
Hier wird der Zugriff auf die Listenelemente mittels Index verdeutlicht.
Mit dem Ausdruck studenten[1,3] werden alle Elemente mit Index ≥ 1 und < 3 ausgewählt (engl. "Slicing").
# Liste "studenten"studenten = ["Max Muster", "Anna Test", "John Doe"]print(studenten) # ['Max Muster', 'Anna Test', 'John Doe']studenten[2] = "Jane Doe" # Zuweisungprint(studenten[0]) # Max Musterprint(studenten[-1]) # Jane Doeprint(studenten[1:3]) # ['Anna Test', 'Jane Doe']
Iterator verwenden
Der Zugriff auf die Listenelemente mittels Iterator kann implizit über die for-Schleife und den "in"-Operator erfolgen,
oder indem man explizit einen Iterator erstellt und diesen durchläuft.
# Durchlaufe Liste mit Hilfe eines Iterators (implizit)for st in studenten:print(st, end=", ")# Durchlaufe Liste mit Hilfe eines Iterators (explizit)iterator = iter(studenten)for st in iterator:print(st, end=", ")
Listen erstellen
Listen können auf unterschiedliche Weisen erstellt werden: (1) durch explizites Aufzählen der Elemente, (2) durch Verwenden einer Schleife, in der die Elemente mittels Klassen-Funktionen angefügt werden, und (3) durch List Comprehension, eine zusammengesetzte Anweisung, bei der nacheinander in einer einzigen Zeile die Definition der Listenelemente, die auszuführende for-Schleife und eine optionale Bedingung angegeben werden.
Im folgenden Beispiel wird die Liste der Zahlen 1, 4, 9, 16, 25 (also die Quadrate der ersten 5 Zahlen) auf drei unterschiedliche Arten erstellt. Als Ergebnis wird jedesmal ein Objekt des Datentyps "list" erstellt. Die Erstellung von Tupeln, Mengen und Dictionaries ist ähnlich, dort werden abhängig von der Datenstruktur andere Operationen verwendet.
(1) Explizites Aufzählen
Beim Erstellen einer Liste durch explizites Aufzählen werden die Werte kommagetrennt in eckige Klammern gesetzt.
Diese Methode eignet sich nur bei kleinen Listen mit wenigen Werten.
a = [1, 4, 9, 16, 25]print(type(a))print(a) # Ausgabe: [1, 4, 9, 16, 25]
(2) for-Schleife und Klassen-Funktionen
Bei der Verwendung der Klassen-Funktionen wird zunächst eine leere Liste erstellt,
danach werden in einer for-Schleife mit append() weitere Werte am Ende der Liste angefügt.
Diese Methode eignet sich auch bei größeren Datenmengen. Mit weiteren Funktionen wie insert, remove, sort werden Elemente an einer
bestimmten Stelle eingefügt, oder Elemente gelöscht, oder die Liste kann sortiert werden.
a = [] # Leere Listefor x in range(1, 6):a.append(x**2) # Anfügen mit appendprint(a) # Ausgabe: [1, 4, 9, 16, 25]
(3) List Comprehension
List Comprehension wird als Kurzform verwendet, um eine Liste mit abkürzenden Syntax zu erstellen:
Man schreibt direkt in die eckigen Klammern die Operation, die auf jedem Element durchzuführen ist, gefolgt von der for-Schleife.
Durch die Verwendung der deklarativen List Comprehension-Syntax kann man das Schreiben expliziter for-Schleifen, die ggf. noch eine Bedingung enthalten,
abkürzen. Anstelle von 5 bis 6 Codezeilen kommt man mit einer einzigen Codezeile aus.
Bei größeren Datenmengen sollte man anstelle von List Comprehension einen List Generator verwenden, die Syntax
ist genau wie bei List Comprehension, nur mit runden anstatt der eckigen Klammern.
Der Unterschied zwischen List Comprehension und List Generator besteht darin, dass Comprehension die komplette Liste
sofort erstellt und im Arbeitsspeicher ablegt, während der Generator nur die gerade benötigten Elemente erstellt und damit Speicher spart.
# List Comprehensiona = [x**2 for x in range(1, 6)]print(a) # Ausgabe: [1, 4, 9, 16, 25]# List Generatora = (x**2 for x in range(1, 6))print(a) # so keine Ausgabe! - Schleife erforderlich# Comprehension mit Bedingunga = [x**2 for x in range(1, 6) if x % 2 == 0]print(a) # Ausgabe: [4, 16]
Listen-Operationen
Liste sind als eine Klasse "list" implementiert, die über eine Reihe von Operationen verfügt, mit deren Hilfe man Listen bearbeiten kann. Wichtige Listenoperationen sind z.B. append - am Ende anfügen, insert() - an bestimmter Position einfügen, pop() - Element an bestimmter Position zurückgeben und aus der Liste entfernen, remove() - Element entfernen, clear() - Liste leeren, sort() - Liste sortieren.
a = [] # Leere Liste# Elemente anfügen mit appendfor i in range(1, 6):a.append(i**2)# Wert 100 einfügen nach Index 2 mit inserta.insert(2, 100)a.sort() # Sortierena.reverse() # Reihenfolge umkehrenprint(a) # Ausgabe: [100, 25, 16, 9, 4, 1]
Listen konvertieren
Eine häufig benötigte Funktionalität im Zusammenhang mit Listen ist das Umwandeln einer Liste in einen String, dies kann z.B. mit Hilfe der join-Funktion erreicht werden. Im folgenden Beispiel haben wir eine Liste mit Studenten-Namen, die wir für die Ausgabe in eine Zeichenkette umwandeln wollen, dabei soll als Trennzeichen für die einzelnen Elemente ein Semikolon verwendet werden.
Python-Code: Liste in String umwandeln mit joinAusgabestud_list = ["Max Muster", "Anna Test", "John Doe"]print("Liste:\n", stud_list)stud_string = ';'.join([str(item) for item in stud_list])print("String:\n", stud_string)

8-2 Tupel
Tupel (engl. tuples) sind geordnete und unveränderbare Kollektionen, die verwendet werden, um zusammengehörende Datensätze (engl. records) zu speichern. Sie erlauben doppelte Mitglieder und werden mit runden Klammern definiert. Die Elemente eines Tupels können über ihren Index ausgewählt werden.
Beispiel: Adressen
Ein Python-Programm verwaltet eine Liste der Standorte einer Hochschule.
Da die Adressen sich nicht ändern, werden hier Tupel verwendet.
Die Zuweisung in Zeile 7 erzeugt einen Fehler, da die Elemente eines Tupels nicht geändert werden können.
# Tupel "adresse"adresse = ("HS KL", "Schoenstrasse", 11)print(adresse)print(adresse[0]) # HS KLprint(adresse[1:3]) # ('Schoenstrasse', 11)print(adresse[-1]) # 11adresse[0] = "Morlauterer Strasse" # Fehler!
8-3 Mengen
Mengen (engl. Sets) sind Sammlungen, die ungeordnet und nicht indiziert sind. Mengen erlauben keine doppelten Mitglieder. Da der Inhalt ungeordnet ist, kann man keinen Index für den Zugriff auf die Elemente benutzen. Eine Menge wird definiert, indem man ihre Elemente in geschweifte Klammern setzt, wie im Beispiel unten.
# Mengen (Sets)menge1 = {1, 2, 3, 4, "a", "b", "c"}menge2 = {3, 4, 5, 6, "c"}menge1.add(8) # neues Element hinzufügenmenge2.discard(6) # Element löschenprint(menge1) # {1, 2, 3, 4, 8, 'a', 'b', 'c'}print(menge2) # {3, 4, 5, 'c'}
Alternativ kann eine Menge mit Hilfe der Funktion set definiert werden. Im Beispiel wird zunächst eine Liste deklariert, und aus der Liste dann eine Menge mit Hilfe der set-Funktion.
Beispiel: Menge aus Liste erzeugen mit setlist = [1, 2, 3] # Listemenge3 = set(list) # Menge
Die Mengen-Datenstruktur ist eine Implementierung des mathematischen Mengenbegriffs und unterstützt Mengenoperationen wie Vereinigung (engl. union), Durchschnitt (engl. intersection), Differenz (engl. difference).
u = menge1.union(menge2) # Vereinigung)print(u) # {1, 2, 3, 4, 5, 8, 'a', 'b', 'c'}diff = menge1.difference(menge2) # Differenzprint(diff) # {1, 2, 8, 'a', 'b'}
Man kann die Set-Elemente mit Hilfe einer for-Schleife durchlaufen oder mit dem Komponenten-Schlüsselwort nachfragen.
8-4 Dictionaries
Dictionaries sind Sammlungen aus Schlüssel-Wert-Paaren, die ungeordnet und änderbar sind. Die eigentlichen Datenwerte ("values") sind über eindeutige Schlüsselwerte ("keys") indexiert. Dictionaries sind eine besonders effiziente Art der Datenspeicherung, allerdings sind die Daten nicht direkt sortierbar. Ist eine Sortierung der Daten in einem Dictionary erforderlich, z.B. nach Schlüssel, muss das Dictionary zunächst in eine Liste überführt werden, die dann sortiert werden kann.
Beispiel: Dictionary "Telefonbuch"
Eine Python-Programm verwaltet die Telefonnummern in einem Telefonbuch.
Jedem Kontakt wird eine Telefonnummer zugeordnet. Schlüssel sind die Namen der Kontakte, Werte sind die Telefonnummern.
In diesem Beispiel-Dictionary können keine zwei Personen mit demselben Namen gespeichert werden!
# Dictionary = Schlüssel-Wert-Paaretelefonbuch = {"Max" : "0171 876654","Anna" : "0151 987654"}# Neue Schlüssel-Wert-Paare hinzufügentelefonbuch["John"] = "0171 123456"telefonbuch.update({"Jane": "0171 123456"})print(telefonbuch) # Telefonbuch ausgeben# Wert über Schlüssel abfragenannasNummer = telefonbuch.get("Anna")print(annasNummer) # 0151 987654telefonbuch_sortiert = dict(sorted(telefonbuch.items()))print(telefonbuch_sortiert)
Python-Dictionaries verfügen über einen Satz eingebauter Funktionen, mittels deren man Elemente hinzufügen, ändern und löschen kann, sowie die Schlüssel oder Werte als Listen extrahieren, insbesondere: mydict.update({key_value_pairs}) - Schlüssel-Wert-Paare hinzufügen, mydict.get(key) - Wert zu gegebenem Schlüssel holen, mydict.items() - Schlüssel-Wert-Paare als Liste zurückgeben, mydict.keys() - Schlüssel zurückgeben, mydict.values() - Werte zurückgeben.
Python-Dictionaries können weiterhin über eine Reihe von Funktionen aus Listen erzeugt und in Listen konvertiert werden. Dies ist z.B. dann nützlich, wenn die gespeicherten Daten sortiert oder anderweitig nachbearbeitet werden müssen.
Beispiel: Dictionary "Telefonbuch" aus Listen erzeugen
In diesem Beispiel wird das Dictionary "Telefonbuch" aus zwei Listen mit Hilfe zweier Funktionen
erzeugt: zip() verknüpft paarweise die Elemente zweier List-Iteratoren,
dict() erzeugt daraus ein Dictionary.
Anschließend werden das Dictionary selber sowie die Schlüssel- und Werte als Liste ausgegeben.
keys = ['Max Muster', 'Anna Test', 'John Doe']values = ['0171 876654', '0151 987654', '0171 123456']telefonbuch = dict(zip(keys, values))print(telefonbuch)print(list(telefonbuch.keys()))print(list(telefonbuch.values()))
9 Funktionen in Python
Eine Funktion ist ein Codeblock, der nur ausgeführt wird, wenn er aufgerufen wird. Funktionen werden einmal definiert und können dann beliebig oft aufgerufen werden. Man kann Daten oder sogenannte Parameter an eine Funktion übergeben. Eine Funktion kann auch Daten/Parameter zurückgeben. Damit eine Funktion Werte zurückgeben kann, benutzt man das Schlüsselwort "return". In Python enthält die Parameterliste üblicherweise eine festgelegte Anzahl an Parametern, es gibt jedoch auch die Möglichkeit, mittels *args oder **kwargs eine variable Anzahl an Parametern zu übergeben (siehe Abschnitt 9-2).
Funktionen kommen auf zweierlei Arten zum Einsatz: zum einen verwendet man vorhandene Funktionen der Python-Pakete, um gewisse Aufgaben durchzuführen. Zum anderen entwickelt man eigene Funktionen für Teilaufgaben und strukturiert damit größere Programme.
9-1 Selbstdefinierte Funktionen
Funktionen werden definiert, indem man nach dem Schlüsselwort def den Namen der Funktion, und danach, in runde Klammern gesetzt, eine Parameterliste angibt. In den nachfolgenden Zeilen stehen die Anweisungen, die zum Codeblock der Funktion gehören. Diese müssen eingerückt sein. Funktionen werden verwendet bzw. aufgerufen, indem man ihren Namen angibt, gefolgt von der Liste der tatsächlichen Argumente, die in Anzahl und Reihenfolge mit der Parameterliste der Funktion übereinstimmen muss.
Funktion ohne Parameter
Die Funktion mit dem Namen my_func() gibt bei jedem Aufruf den Text "Hallo" auf der Konsole aus.
Die Parameterliste ist leer, d.h. zwischen den runden Klammern steht nichts.
# (1) Funktion definierendef my_func():print("Hallo!")# (2) Funktion verwendenmy_func() # Ausgabe: Hallo!my_func() # Ausgabe: Hallo!
Funktion mit Übergabe-Parameter
Die Funktion mit dem Namen my_func() gibt ihre beiden Parameter auf der Konsole aus, getrennt durch ">>".
Jeder der Parameter darf ein beliebiges Objekt sein. Der Funktionsaufruf in Zeile 9 führt zu der Fehlermeldung
"TypeError: my_func() missing 1 required positional argument: 'text'", da für den zweiten Parameter kein Wert übergeben wurde.
# (1) Funktion definierendef my_func(nr, text):print(nr, '>>', text)# (2) Funktion verwendenmy_func(1, "Hallo") # Ausgabe: 1 >> Hallomy_func(2, "zusammen!") # Ausgabe: 2 >> zusammen!my_func(3, [1,2,3,4]) # Ausgabe: 3 >> [1, 2, 3, 4]my_func("X", 4) # Ausgabe: X >> 4my_func(4) # Fehler! Das zweite Argument fehlt
Funktion mit Standard-Übergabe-Parameter
# (1) Funktion definierendef my_func(text = "kein Text übergeben"):print(text)# (2) Funktion verwendenmy_func() # Ausgabe: kein Text übergebenmy_func("Übergebener Wert") # Ausgabe: Übergebener Wertmy_func(text = "Übergebener Wert") # Ausgabe: Übergebener Wert
Funktion mit Rückgabewert
Eine Funktion kann auch Daten/Parameter als Rückgabewert zurückliefern, diese können in der aufrufenden Funktion in Berechnungen oder Ausgaben weiter verwendet werden.
Damit eine Funktion einen Wert zurückgibt, wird das Schlüsselwort return verwendet.
Beispiel 1
Beispiel 1 definiert die Funktion myfunc(), die das Doppelte des Parameters x zurückgibt.
# (1) Funktion definierendef my_func(x):return x*2# (2) Funktion verwendenprint(my_func(4)) # Ausgabe: 8print(my_func(5)) # Ausgabe: 10
Beispiel 2
Beispiel 2 zeigt, wie eine benutzerdefinierte Funktion f(x,y) = sin(x)*exp(-y) definiert wird.
Die Parameter x und y müssen reelle Werte sein. Die Funktion funktioniert nicht für Parameter x, y, die Listen sind,
also erzeugt f(list1, list2) einen Fehler.
Wenn eine Funktion in Python Listenparameter akzeptieren soll, muss sie zuerst mit der NumPy-Function vectorize
in eine vektorisierte Form umgewandelt werden.
# Definiere die Funktion ffrom numpy import pi, sin, expdef f(x, y) :return sin(x)*exp(-y)# Verwende die Funktion fz = f(pi/4, 1); print(z)# Verwende vektorisierte Version der Funktion ffvec = np.vectorize(f)z = fvec([pi/4, pi/2], [1, 2]); print(z)
9-2 Funktionen mit variabler Parameterliste
Wenn nicht bekannt ist, wie viele Argumente an die Funktion übergeben werden, fügt man vor dem Parameternamen in der Funktionsdefinition ein * hinzu, d.h. man verwendet den Unpacking-Operator (*), um den Parameter "auszupacken". Auf diese Weise erhält die Funktion ein Tupel von Argumenten und kann entsprechend auf die Elemente zugreifen. Die variablen Parameter bezeichnet man üblicherweise mit *args, das ist jedoch lediglich eine Namenskonvention. Für noch mehr Flexibilität können Schlüsselwertargumente mit dem Bezeichner **kwargs verwendet werden.
Beispiel: Funktion mit variabler Parameterliste
Die Funktion anzahl_arg() hat eine variable Parameterliste und gibt die Anzahl ihrer Parameter aus.
Der Funktionsaufruf in Zeile 5 erzeugt die Ausgabe 1, da die Funktion hier nur ein Argument, nämlich die Liste [1, 2, "Los"], erhält.
Der Funktionsaufruf in Zeile 6 erzeugt die Ausgabe 2, da die Funktion hier zwei Argumente, nämlich die Liste [1, 2] und den String "Los!"
erhält.
Der Funktionsaufruf in Zeile 7 erzeugt die Ausgabe 3, da der Funktion hier drei Argumente, nämlich die Zahlen 1 und 2 sowie den String "Los!"
übergeben werden.
Würde man den * vor dem Namen des Parameters weglassen, könnte hier nur ein einziger Parameter übergeben werden,
z.B. ein Objekt oder eine Liste.
# (1) Funktion definierendef anzahl_arg(*args):return len(args)# (2) Funktion verwendenprint(anzahl_arg([1, 2, "Los!"])) # Ausgabe : 1print(anzahl_arg([1, 2], "Los!")) # Ausgabe: 2print(anzahl_arg(1, 2, "Los!")) # Ausgabe: 3
9-3 Lambda-Funktionen
Eine Lambda-Funktion ist eine spezielle Art von Funktion, die für kurze einzeilige Befehle verwendet wird und anstelle von def das Schlüsselwort lambda verwendet. Sie kann eine beliebige Anzahl von Parametern / Argumenten annehmen, aber nur einen Ausdruck (Befehl) haben. Die erste Lambda-Funktion in unserem Beispiel fügt der als Argument übergebenen Zahl den Wert 10 hinzu. Die zweite Lambda-Funktion hat zwei Argumente, a und b, die sie multipliziert.
# Erste Lambda-Funktion "add":add = lambda a : a + 10# Aufruf der Funktion:print(add(5)) # Ausgabe: 15# Zweite Lambda-Funktion "mult":mult = lambda a, b : a * b# Aufruf der Funktion:print(mult(5, 2)) # Ausgabe: 10
9-4 Globale und lokale Variablen
Variablen, die außerhalb einer Funktion erstellt werden, nennt man globale Variablen. Globale Variablen können innerhalb und außerhalb von Funktionen verwendet werden. Wenn man eine Variable innerhalb einer Funktion erstellt, ist diese Variable lokal und kann nur in dieser Funktion verwendet werden. Um eine globale Variable innerhalb einer Funktion zu definieren, kann man das Schlüsselwort global verwenden.
Selbsttest: Funktionen
Quiz: Python Funktionen Teil 1 (5 Fragen)
Testen Sie Ihre Kenntnisse über die Verwendung von Funktionen in Python mit dem Quiz "Python Funktionen Teil 1".
Die Themen dieses Quiz sind das Definieren und Verwenden selbstgeschriebener Funktionen sowie korrekte Parameterübergabe.
Starte das Quiz
Quiz: Python Funktionen Teil 2 (5 Fragen)
Testen Sie Ihr Verständnis fortgeschrittener Konzepte über die Verwendung von Funktionen in
Python mit dem Quiz "Python Funktionen Teil 2".
Die Themen dieses Quiz sind: Lambda-Funktionen, Annotationen, Docstrings, und Vektorisierungsfunktionen.
Starte das Quiz
10 Klassen und Vererbung
Python ist eine objektorientierte Programmiersprache, deren komplette Funktionalität über Klassen abgebildet ist. Die Strukturierung von Python-Skripten mittels Klassen ist nicht zwingend erforderlich und bei kleineren Programmen auch nicht notwendig. Bei der Entwicklung größerer Software-Komponenten, die ggf. auch graphische Benutzeroberflächen enthalten, kommt man auch in Python an Klassen und Vererbung nicht vorbei.
Objektorientierte Programmierung (OOP)
ist ein Modell bzw. Design höherer Programmiersprachen, das ein Programm mittels Objekten strukturiert,
die Attribute und Methoden bzw. Aktionen besitzen.
OOP-Konzepte:
Eine Klasse ist ein Objekt-Konstruktor zum Erstellen von neuen Objekten einer Klasse, diese nennt man auch die Instanzen der Klasse.
Attribute einer Klasse sind Variablen, die zu der Klasse gehören und die Eigenschaft der Objekte beschreiben.
Methoden einer Klasse sind Funktionen, die innerhalb einer Klasse definiert werden und Aktionen beschreiben, die auf den Daten der Klasse durchgeführt werden.
OOP-Vorteile:
OOP ermöglicht eine höhere Abstraktion bei der Programmierung,
OOP ermöglicht die Kapselung zusammengehörender Attribute und Aktionen,
OOP ermöglicht die Wiederverwendbarkeit von Code. Durch Vererbung kann eine Subklasse die Attribute und Methoden einer Basisklasse erben.
Klasse eines Python-Objektes herausfinden
Die Klasse eines Python-Objektes kann mit Hilfe der type-Anweisung herausgefunden werden.
Wenn man mit type() den Typ einer Zahl, einer Zeichenkette, oder einer Liste ausgibt, wird die passende Klasse
ausgegeben, mit deren Hilfe das entsprechende Objekt erzeugt wurde.
zahl = 1.23text = 'Hallo'mylist = [1, 4, 9, 16, 25]print("Python-Objekte und ihre Klassen: ")print(type(zahl)) # Ausgabe: <class 'float'>print(type(text)) # Ausgabe: <class 'str'>print(type(mylist)) # Ausgabe: <class 'list'>
10-1 Klassen in Python deklarieren
In Python benutzt man für die Definition einer neuen Klasse das Schlüsselwort class, danach wird der Name der Klasse angegeben, gefolgt von Doppelpunkt, und danach eingerückt die Methoden der Klasse. Eine Methode einer Klasse ist eine Funktion, die innerhalb dieser Klasse definiert wird und als ersten Parameter einen Verweis namens self auf die Instanz enthält, von der sie aufgerufen wurde. Man unterscheidet zwischen Instanzmethoden, die zu einer Instanz der Klasse gehören (also zu einem Objekt der Klasse) und Klassenmethoden, die der Klasse im allgemeinen gehören und nur sparsam eingesetzt werden sollten.
Python-Klassen haben eine __init __ ()-Methode, die implizit beim Erstellen eines neuen Klassenobjektes ausgeführt wird. Die "__init __ ()"-Methode wird wie ein Klassenkonstruktor verwendet, um Objekteigenschaften zu setzen oder andere Vorgänge, die beim Erstellen des Objekts erforderlich sind, durchzuführen.
Eine Besonderheit bei der Verwendung von Membervariablen und Instanzmethoden einer Klasse in Python ist, dass bei interner Verwendung Schlüsselwort self stets vorangestellt werden muss.
Beispiel: Wir deklarieren eine Klasse Auto, mit der wir neue Auto-Objekte erzeugen wollen. Ein Auto hat die Eigenschaften Hersteller und Modell und eine Methode "ausgeben()", die die Eigenschaften des Autos zu einer Zeichenkette zusammenbaut und ausgibt.
- Zeile 2-4: Die"__init __ ()"-Funktion setzt aktuellen Werte für hersteller und modell. Der Parameter "self" ist eine Referenz auf die aktuelle Instanz der Klasse und wird für den Zugriff auf Variablen der Klasse verwendet. Der self-Parameter muss bei allen Methoden der Klasse als erster Parameter der Parameterliste angegeben werden.
- Zeile 5-6: Die Methode ausgeben() erstellt eine Textausgabe aus den Eigenschaften des Klassenobjektes.
- Zeile 8-10: Erstelle zwei neue Klassenobjekte und gebe sie aus.
- Zeile 13-14: Lösche die Klassenobjekte. Dies is optional. Mit dem Schlüsselwort "del" wird das Objekt zerstört und vom Speicher gelöscht.
# auto.pyclass Auto:def __init__(self, hersteller, modell):self.hersteller = herstellerself.modell = modelldef ausgeben(self):print("Hersteller: " + self.hersteller + ", Modell: " + self.modell)# Erstelle neue Klassenobjekte, gebe sie aus, und lösche sie wiedermy_auto1 = Auto("Audi", "A3")my_auto2 = Auto("BMW", "i3")my_auto1.ausgeben() # Ausgabe: Hersteller: Audi, Modell: A3my_auto2.ausgeben() # Ausgabe: Hersteller: BMW, Modell: i3del my_auto1del my_auto2
10-2 Vererbung in Python
Vererbung ermöglicht es, Klassen zu definieren, die alle Methoden und Eigenschaften einer anderen Klasse erben. Die übergeordnete Klasse, von der geerbt wird, nennt man Basisklasse. Die untergeordnete Klasse, die von der Basisklasse Eigenschaften und Methoden erbt, nennt man Subklasse oder Kindklasse. In Python wird eine Subklasse definiert, indem man nach dem Klassennamen den Namen der Basisklasse in runde Klammern setzt.
Beispiel: Basisklasse Fahrzeug, Subklasse Auto
Wir definieren eine Basisklasse "Fahrzeug" und eine Subklasse "Auto".
Die Subklasse Auto erbt die Eigenschaften und Funktionen von "Fahrzeug" und hat eine
weitere Eigenschaft "farbe" sowie eine zusätzliche Methode "set_farbe()", mit der die Farbe
geändert werden kann.
Klassen-Hierarchien
Die Klassenhierarchie zusammengehöriger Python-Klassen, d.h. die Beziehungen zwischen den Klassen, können noch vor der Programmierung durch ein UML-Klassendiagramm visualisiert werden.
In einem UML-Klassendiagramm wird jede Klasse in ein Rechteck mit drei getrennten Bereichn gesetzt: Namen der Klasse, Klassen-Attribute und Klassen-Methoden. Weiterhin werden die Beziehungen zwischen den Klassen durch Pfeilverbindungen eingezeichnet.
UML-Klassendiagramm

Python-Klassen auf Module verteilen
Klassen und Subklassen können in demselben Python-Modul untergebracht werden, z.B.
werden in dem folgenden Beispiel die Klassen Fahrzeug, Auto und LKW nacheinander in das Modul
fahrzeug.py plaziert.
Für größere Klassen hat es sich bewährt, ein eigenes gleichnamiges Modul zu verwenden,
dann würde man die Klasse fahrzeug in das Modul fahrzeug.py platzieren, die Klasse auto in das Modul
auto.py etc.
fahrzeug.py: Klassendefinitionen
#Modul fahrzeug.pyclass Fahrzeug:"""Basisklasse für Fahrzeuge"""def __init__(self, hersteller, modell):self.hersteller = herstellerself.modell = modelldef ausgeben(self):print("Hersteller:", self.hersteller, ", Modell:", self.modell,end =", ")class Auto(Fahrzeug):""" Subklasse für Autos """def __init__(self, hersteller, modell, farbe="silber"):super().__init__(hersteller, modell)self.farbe = farbedef ausgeben(self):print("[Auto]", end =" ")super().ausgeben()print("Farbe: ", self.farbe)def set_farbe(self, farbe):self.farbe = farbe
fahrzeug.py: Erläuterung des Codes
Das Modul fahrzeug.py enthält lediglich die Klassendefinitionen, hier werden
noch keine neue Instanzen der Klassen angelegt und das Modul fahrzeug.py kann nicht ausgeführt werden.
- Zeile 2-9: Definition der Basisklasse für Fahrzeuge
- Zeile 11: Definition der Subklasse Auto.
- Zeile 13-15: Mit "super.__init__" wird die Initialisierungsmethode der Basisklasse ausgeführt. Danach wird der Wert des Attributs farbe gesetzt, das nur zur Subklasse gehört.
- Zeile 16-19: Definition der Methode "ausgeben()", die durch super().ausgeben() den Code der Basisklasse ausführt und zusätzlich neue Informationen hinzufügt.
- Zeile 20-21: Definition der Methode "set_farbe()", die nur der Subklasse gehört
main.py: Verwendung der Klassen aus fahrzeug.py
Nachdem Basisklasse und Subklasse in fahrzeug.py definiert wurden, kann man damit
neue Instanzen von Fahrzeugen und Autos anlegen und ihre Methoden ausführen.
Damit die Klassen aus dem Modul fahrzeug.py in dem Modul main.py verwendet werden können,
müssen sie zunächst importiert werden
from fahrzeug import Fahrzeug, Autodef main():# Erstelle Instanz der Basisklasse Fahrzeugmy_bmw = Fahrzeug("BMW", "x3")my_bmw.ausgeben()# Erstelle Instanz der Subklasse Automy_audi = Auto("Audi", "A3")my_audi.ausgeben()# Farbe ändern und erneut ausgebenmy_audi.set_farbe("rot")my_audi.ausgeben()# Einstiegspunkt der Anwendungif __name__ == "__main__":main()
main.py: Erläuterung des Codes
Die main.py ist der Einstiegspunkt der Anwendung.
Wir erstellen eine Instanz my_bmw der Basisklasse Fahrzeug und geben my_bmw aus,
danach eine Instanz my_audi der Subklasse Auto, geben my_audi aus, ändern die Farbe, und geben
my_audi nochmal aus.
Ausgabe
Hersteller: BMW , Modell: x3, [Auto] Hersteller: Audi , Modell: A3, Farbe: silber [Auto] Hersteller: Audi , Modell: A3, Farbe: rot
Beispiel: Subklasse LKW
Wir definieren eine weitere Subklasse "LKW" der Basisklasse "Fahrzeug".
Die Subklasse LKW hat zusätzlich zu den von "Fahrzeug" geerbten Eigenschaften noch das Attribut "tonnage" mit
der Setter-Methode set_tonnage() und überschreibt die ausgeben()-Methode mit einer eigenen Definition.
Hier wird die Methode "ausgeben()" der Basisklasse so überschrieben, dass der Text "LKW" der Ausgabe vorangestellt wird,
und die Tonnage an die Ausgabe angefügt wird.
class LKW(Fahrzeug):def __init__(self, hersteller, modell, tonnage = 3):super().__init__(hersteller, modell)self.tonnage = tonnagedef set_tonnage(self, tonnage):self.tonnage = tonnagedef ausgeben(self):print("[LKW]:", end =" ")super().ausgeben()print("Tonnage: ", self.tonnage)def set_achsenkonfig(achsen):pass
Das Schlüsselwort pass wird in Python als Platzhalter für Code verwendet, der erst noch implementiert werden muss.
10-3 UML-Klassendiagramme in Python
UML-Klassendiagramme sind nützlich, um eine visuelle vereinfachte Darstellung zusammenhängender Klassen zu erzeugen. Für die Erstellung von UML-Klassendiagrammen in Python gibt es unterschiedliche Tools und Extensions, z.B. PlantUML, Mermaid JS und pyreverse. PlantUML- und Mermaid-Diagramme werden mit Hilfe einer eigenen Markdown-Syntax erstellt, wie im folgenden Beispiel, das mit Hilfe der PlantUML-Extension in Visual Studio Code erstellt wurde.
UML-Klassendiagramm mit PlantUML
Ein UML-Klassendiagramm mit PlantUML ist einfach eine Textdatei mit der Endung *.puml,
mit zwei Annotationen @startuml und @enduml, die Anfang und Ende der Datei markieren.
Die Klassen mit ihren Attributen und Methoden werden mittels einer Markdown Syntax erstellt.
Eine Klasse wird mit dem Schlüsselwort class eingeleitet, gefolgt von dem Namen der Klasse, und dem Attributen und Methoden, die in geschweifte Klammern gesetzt werden. Sichtbarkeit von Attributen und Methoden wird durch das Voranstellen der Symbole - (privat), + (öffentlich), # (protected) beschrieben. Beziehungen zwischen Klassen werden durch verschiedene Pfeilverbindungen erzeugt: <|-- für Vererbung, -- für Assoziation, o-- für Aggregation, *-- für Komposition.
@startuml FahrzeugUML
class Fahrzeug {
- hersteller
- modell
+ Fahrzeug(hersteller, modell)
+ ausgeben()
}
class Auto {
- farbe
+ Auto(hersteller, modell, farbe)
+ set_farbe(farbe)
+ ausgeben()
}
class LKW {
- tonnage
+ LKW(hersteller, modell, tonnage)
+ set_tonnage(tonnage)
+ ausgeben()
}
Fahrzeug <|-- Auto
Fahrzeug <|-- LKW
@enduml
UML-Klassendiagramm mit PlantUML
Das Diagramm wurde in Visual Studio Code mit Hilfe der PlantUML Extension erstellt. Eine Voransicht des UML-Klassendiagramm wird mit Hilfe der Tastenkombination Alt + D angezeigt.
Die PlantUML-Markdown-Sprache bietet umfangreiche Beschreibungsmöglichkeiten zum Erstellen von Klassendiagrammen. Attribute und Parameter können mit Datentypen versehen werden, Beziehungen können beschriftet werden, und vieles mehr.
Reverse Engineering: UML-Klassendiagramm aus Code erstellen
UML-Klassendiagramme können in Python mit Hilfe des Kommandozeilen-Tools
pyreverse
erstellt werden, das als Teil des Paketes pylint mitgeliefert wird.
Pylint ist ein Python-Paket für statische Codeanalyse und dazu gehört insbesondere auch
das Reverse Engineering, d.h. das Erstellen von UML-Klassendiagrammen aus vorhandenem Python-Code.
Pylint installieren
Bei der Installation von pylint bzw. pyreverse sind einige Besonderheiten zu beachten.
- Vor der Verwendung muss Pylint installiert werden, wie üblich mit pip.
pip install pylint
- Weiterhin sollte auch die Graph-Visualisierungssoftware Graphviz installiert werden, da diese von pyreverse als Backend verwendet wird.
- Die Verwendung von Pylint wird im Kontext einer globalen Python-Installation empfohlen, da in diesem Fall die Pfade zu den Python-Programmen direkt dem Systempfad (unter Windows: Systemumgebungsvariable PATH) hinzugefügt werden. Falls man pylint in einer lokalen Python-Installation verwendet, z.B. einem Conda-Environment, werden ggf. pylint und pyreverse nicht gefunden, und man muss die Pfadangaben in der Entwicklungsumgebung einstellen.
Pyreverse-Befehle
Pyreverse-Befehle habe die allgemeine Form pyreverse [optionen] pakete
und werden in der Kommandozeile eingegeben.
Mittels der Optionen kann man z.B. Pakete filtern und das Ausgabe-Format festlegen.
Hilfe zu den Befehlen ausgeben:
pyreverse --help
Gehe mit cd in den Ordner, wo sich das Paket oop befindet. Erzeuge ein UML-Diagramm für das Paket oop im Ausgabeformat png.
cd \pfad\zu\oop pyreverse oop --output png .
Gehe mit cd in den Ordner, wo sich das Paket oop befindet. Erzeuge ein UML-Diagramm für das Paket oop im Ausgabeformat svg, verwende qualifizierte Modulnamen (hier: oop.fahrzeug.Fahrzeug).
cd \pfad\zu\oop pyreverse oop --output svg --verbose --module-names=true
Verzeichnisstruktur des Pakets oop
Der Ordner oop enthält eine Datei __init__py und wird dadurch als Paket gekennzeichnet.
Das Modul fahrzeug.py enthält die Basisklasse Fahrzeug und die
Subklassen Auto und LKW.
├─ oop │ ├─ __init__.py │ ├─ fahrzeug.py
UML-Klassendiagramm

Die mit Pyreverse erzeugten Klassendiagramme sind schlichter als die mit PlantUML oder Mermaid JS erzeugten, haben jedoch den Vorteil, direkt aus dem Quellcode der Klassen generiert zu werden. Man spart sich damit die doppelte Arbeit, zusätzlich zur Programmierung die Klassen in einer Markdown-Sprache noch einmal beschreiben zu müssen.
11 Fehlerbehandlung
Bei der Programmierung können verschiedene Arten von Fehlern auftreten, die auf unterschiedliche Arten behandelt werden.
- Syntax-Fehler: Syntax-Fehler passieren noch während der Programmierung, dadurch, dass die Regeln der Programmiersprache nicht eingehalten werden. Syntax-Fehler in Python entstehen z.B durch falsche Einrückung, Code an falscher Stelle platzieren, fehlende Import-Anweisungen, falsche Angabe der Funktionsnamen. Syntax-Fehler werden vom Interpreter erkannt und in der Entwicklungsumgebung angezeigt.
- Laufzeitfehler: Laufzeitfehler treten erst während der Programmausführung auf. Sie entstehen durch falsche Benutzereingaben, Endlosschleifen die zum Speicherüberlauf führen, Teilen durch Null usw. Dadurch sind sie nicht immer vorab erkennbar, denn das Programm ist ja syntaktisch korrekt und wurde vom Compiler / Interpreter übersetzt. Für den Umgang mit Laufzeitfehlern gibt es spezielle Sprachkonstrukte, die dazu dienen, Laufzeitfehlern systematisch zu behandeln und eventuelle negative Auswirkungen zu verhindern.
Die Fehlerbehandlung wird in Python durch Verwendung der Befehle try .. except und raise durchgeführt. Weiterhin gibt es verschiedene vordefinierte Fehlerklassen, die den unterschiedlichen Laufzeitfehlern entsprechen: TypeError, ValueError, ZeroDivisionError, FileNotFoundError [...], sowie eine generische Exception, die man verwenden kann, wenn jeder mögliche Ausnahmefehler abgefangen werden soll.
11-1 Fehler mit try-except behandeln
Der try-except-Befehl wird mit dem Schlüsselwort try eingeleitet, gefolgt von den zu prüfenden Codezeilen.
Danach folgt das Schlüsselwort except, ergänzt durch eine Fehlerklasse, z.B. Exception as e,
und schließlich der Code, der im Fehlerfall ausgeführt werden soll.
Die Fehlerbehandlung ist im einfachsten Fall eine print-Ausgabe mit der Fehlermeldung,
kann jedoch auch das Erzeugen eines neuen Folgefehlers mittels raise enthalten.
Wirkung: Falls der Code im try-Block fehlerfrei ist, wird er ausgeführt und der except-Teil wird ignoriert. Falls jedoch irgendwo im try-Block ein Fehler auftritt, wird die Programmausführung im try-Block an der Stelle abgebrochen und es werden die Anweisungen im except-Teil ausgeführt.
try-except-1.pyimport pandas as pdtry:df = pd.read_csv("daten.csv")print(df)except Exception as e:print("Fehler!", e)
Der Code kann getestet werden, indem zunächst das Programm ohne vorhandene Daten-Datei daten.csv ausgeführt wird, dies führt zur Ausgabe der Fehlermeldung "Fehler! [Errno 2] No such file or directory: 'daten.csv'". Danach den Code mit vorhandener Daten-Datei ausführen: falls sie im korrekten Verzeichnis ist und auch der Inhalt einer gültigen csv-Datei entspricht, wird das Einlesen funktionieren. Ansonsten können beim Einlesen einer Datei noch weitere Fehler auftreten, die behandelt werden müssen.
11-2 Mehrfache Fehlerbehandlung
Eine try-except-Anweisung kann mehrere except-Teile haben, wobei jeder except-Block eine Fehlerbehandlung für einen eigenen Fehler enthält. Tritt ein Fehler im try-Block auf, wird der dazu passende except-Block ausgeführt und die try-catch-Anweisung wird verlassen. Dies ist dann nützlich, wenn bei einem bestimmten Code-Abschnitt mehrere Fehler auftreten können, erwartete und unerwartete, die auf unterschiedliche Arten behandelt werden sollen.
Einlesen einer Datei mit Mehrfach-Fehlerbehandlung
Beim Einlesen von Daten aus einer Datei können unterschiedliche Fehler auftreten,
einerseits bekannte Fehler (die einzulesende Datei ist ggf. falsch benannt oder nicht vorhanden, oder
die Daten liegen im falschen Format vor), andererseits auch unbekannte Fehler, mit deren
Auftreten der Programmierer nicht rechnet.
Der Beispielcode erwartet als Eingabe eine Textdatei daten.csv, die eine Spalte aus Zahlenwerten enthält. Falls die Datei nicht vorhanden oder falsch benannt ist, wird der except-Block in Zeile 12 ausgeführt. Falls der erste Eintrag in der Datei eine Spaltenüberschrift ist, z.B. "Temp", wird die Konvertierungsanweisung zahl = float(zeile.strip()) zu einem Fehler führen und die Fehlerbehandlung in Zeile 14 wird ausgeführt. Falls ein anderer unbekannter Fehler auftritt, wird dieser mit dem dritten except-Block abgefangen und behandelt.
daten.csvTemp 21.14 21.58 23.99 21.96try-except-2.py
daten = [] # Leere Listetry:daten_datei = open('daten.csv')while True:zeile = daten_datei.readline() # Zeile einlesenif not zeile: # Abbruch, wenn keine Zeilen mehr vorhandenbreakzahl = float(zeile.strip()) # String in Zahl konvertierendaten.append(zahl)print(daten)except FileNotFoundError as err:print("Datei wurde nicht gefunden.", err)except ValueError as err:print("Konvertierungsfehler. Bitte Dateiinhalt überprüfen.", err)except Exception as err:print(f"Unbekannter Fehler {err=}, {type(err)=}")
11-3 Fehler mit raise erzeugen
Der Python-Befehl raise wird verwendet, um an einer bestimmten Stelle absichtlich einen Fehler zu generieren. An der Stelle, wo das Programm einen Fehler erzeugen soll, schreibt man das Schlüsselwort raise, gefolgt von dem Namen der Fehlerklasse, evtl. auch gefolgt von einem String-Parameter, der die Fehlerbeschreibung enthält.
Fehler mit raise generieren und mit try-except behandeln
Dies Beispiel enthält zwei beispielhafte Verwendungen der Fehlergenerierung: einmal
wird raise verwendet, um die Korrektheit der Parameterübergabe zu überprüfen,
und dann, um zu signalisieren, dass eine Methode noch nicht implementiert wurde.
class Student:def __init__(self, name):if not isinstance(name, str):raise TypeError("Name des Studenten muss ein String sein!")self.name = namedef ausgeben(self):print("Student:", self.name, end =", ")def note_berechnen(self):raise NotImplementedErrortry:std = Student(name=1234)std.ausgeben()except TypeError as e:print("Fehler: ", e)
In der __init__-Methode wird mit raise ein TypeError generiert, falls der Parameter name
keine Zeichenkette ist. In Zeile 11 wird ein Student std mit dem Wert 1234 für den Parameter name deklariert,
dies löst den TypeError aus, der dann in Zeile 14 behandelt wird.
Die Fehlermeldung lautet: "Fehler: Name des Studenten muss ein String sein!"
12 Python vs MATLAB, R, C
Dieser Abschnitt fasst Gemeinsamkeiten und Unterschiede der Programmierung mit Python im Vergleich zur Programmierung mit anderen Programmiersprachen (C, MATLAB, R) zusammen. Vorab: Python hat mehr Ähnlichkeiten mit den wissenschaftliche Sprachen MATLAB oder R als mit den C-ähnlichen Sprachen (C, C++, Java). Man kann mit Python zwar auch Software-Anwendungen wie z.B. Webanwendungen mit Datenbankanbindung entwickeln. Der Fokus der Programmiersprache Python liegt jedoch auf spezialisierten wissenschaftlichen Anwendungen, z.B. im Bereich KI / Machine Learning, Numerik, oder Cyber Security, dafür gibt es alle benötigten Bibliotheken und Tools.
Was sind also die Besonderheiten, die Python am stärksten von anderen Programmiersprachen unterscheiden? Die folgende Liste führt vor allem diejenigen Unterschiede an, die einem Umsteiger bei der Programmierung am stärksten auffallen.
- Interaktive Benutzerkonsole
Der Python-Interpreter hat eine interaktive Benutzerkonsole. Dies ist anders als in C oder Java, und ähnlich wie in R oder MATLAB. - Einrückungen
Einrückungen haben in Python eine syntaktische Bedeutung, sie bezeichnen einen Codeblock, d.h. eine Reihe zusammengehöriger Anweisungen. Dies ist anders als in C und Java, wo man geschweifte Klammen verwendet, um Codeblöcke zu kennzeichnen. - Variablen deklarieren
Variablen können ohne Angabe eines Datentyps verwendet werden ("dynamische Typbindung"). Dies ist anders als in C oder Java, und ähnlich wie in R oder MATLAB. - Bibliotheken
Python verfügt über umfangreiche Bibliotheken für Machine Learning (Datenverwaltung, Datenanalyse und Datenvisualisierung). Dies ist anders als in C oder Java, und ähnlich wie in R oder MATLAB. Python verfügt über umfangreiche Bibliotheken für Kryptografie und Cyber Security. Dies ist ähnlich wie in C++ und Java, und anders wie in R oder MATLAB! - Objektorientierte Programmierung
Python kann sowohl prozedural als auch objektorientiert programmiert werden. Dies ist anders als in C oder Java: C ist nur prozedural, Java ist nur objektorientiert, und ähnlich wie in R oder MATLAB: dort kann man Klassen verwenden, oder auch nicht. Python-Klassen verfügen nicht über eine Zugriffssteuerung (private / protected / public) auf ihre Membervariablen und Methoden.
Wie jede Programmiersprache ist Python ein Werkzeug, das für bestimmte Anwendung besonders gut geeignet ist, andererseits jedoch nicht bei allen Anwendungen die beste Lösung. Für Echtzeitanwendungen sind die Programmiersprachen C oder C++ das Mittel der Wahl. Für große Anwendungen mit komplexer Softwarearchitektur, wo bei Entwurf und Entwicklung die komplette Palette der objektorientierten Programmierung eingesetzt werden muss, bietet Java die benötigte Funktionalität.
12-1 Python vs MATLAB
Python und MATLAB sind Hochsprachen für wissenschaftliche Anwendungen und haben Gemeinsamkeiten, die das Erlernen und Verwenden der jeweils anderen Sprache erleichtern. Während MATLAB eine lizenzpflichtige Plattform ist, die insbesondere Ingenieure bei der Durchführung numerischer Berechnungen und Simulationen unterstützt, ist Python zusammen mit den zugehörigen Bibliotheken und Frameworks kostenlos verfügbar. Python hat dieselben Sprachelemente wie MATLAB: Variablen, if-else-Anweisungen, Schleifen (while, for), Funktionen.
- Python und MATLAB sind skriptbasiert. Eine main-Funktion als Einstiegspunkt ist in beiden Sprachen nicht erforderlich.
- Python und MATLAB verwenden eine dynamische Typbindung bei Variablen, d.h. man muss den Datentyp nicht angeben.
- Anweisungsblöcke werden in MATLAB durch Einrückung gekennzeichnet und mit end abgeschlossen, z.B. bei if-else, bei Schleifen und bei Funktionen.
- Anweisungen können, müssen aber nicht mit Semikolon abgeschlossen werden. Dies ist in beiden Sprachen gleich.
- Funktionen werden in Python mit dem Schlüsselwort def deklariert, in MATLAB mit function.
- Die Plotting-Funktionalität ist in MATLAB und Python's Matplotlib sehr ähnlich.
12-2 Python vs C
Während Python eine Hochsprache für wissenschaftliche Anwendungen (Datenanalyse, KI) ist und viele Bibliotheken für genau diese Anwendung anbietet, ist C eine hardwarenahe Sprache mit wenig Bibliotheken und für Performance ausgelegt. Eine Verbindung zwischen Python und C gibt es doch: Wenn wir ein Python-Programm schreiben, wird das Programm vom Python-Interpreter ausgeführt. Dieser Interpreter ist in der Sprache C geschrieben. Python hat dieselben grundlegenden Sprachelemente wie C: Variablen, if-else-Anweisungen, Schleifen (while, for), Funktionen. C hat darüber hinaus spezielle Zeigervariablen "Pointer", mit denen man direkt auf Speicherbereiche zugreifen kann.
- In Python ist eine main-Funktion nicht zwingend erforderlich. Bei größeren Programmen ist es sinnvoll, eine eigene main-Funktion als Einstiegspunkt des Programms zu deklarieren.
- Anweisungen können, müssen aber nicht mit Semikolon abgeschlossen werden.
- Anweisungsblöcke werden in C mit geschweiften Klammern markiert, in Python hingegen durch Einrückung gekennzeichnet.
- Python verwendet im Unterschied zu C eine dynamische Typbindung, d.h. bei Variablen muss der Datentyp nicht angegeben werden.
- Funktionen werden in Python mit dem Schlüsselwort def deklariert.
- Mit Python kann man sowohl prozedural als auch objektorientiert programmieren, d.h. im Unterschied zu C kann man in Python Klassen verwenden.
Nächste Schritte
In Teil 2: Python Pakete installieren wird beschrieben, wie man mit Hilfe der Paketverwaltungssysteme pip und conda Python-Pakete installiert, aktualisiert und deinstalliert, wie man für verschiedene Projekte passende Anwendungsumgebungen ("environments") erstellt und wie man die installierten Pakete in Python-Skripten mit Hilfe der import-Anweisung korrekt importiert. Die Entwicklung selbstdefinierter Pakete, mit deren Hilfe man größere Projekte strukturieren kann, wird an einem Beispiel vorgestellt.
Teil 3: Python Bibliotheken dieses Python-Tutorials gibt eine Übersicht über die wichtigsten Bibliotheken für Datenanalyse und Maschinelles Lernen. Zunächst werden die Pakete NumPy, Matplotlib und Pandas vorgestellt, die für Datenvorbereitung und -Visualisierung verwendet werden. Anschließend wird die Verwendung der Machine Learning-Bibliothek Scikit-Learn am Beispiel einer Klassifikation für die Vorhersage von Ausfällen erklärt. Schließlich wird die Erstellung eines Künstlichen Neuronalen Netzwerkes für die Bilderkennung mit Hilfe der Bibliotheken Keras und Tensorflow illustriert.
Die vollständige und detaillierte Python-Dokumentation kann auf der offiziellen Python-Webseite https://docs.python.org/3/tutorial/ nachgeschlagen werden.
Autoren, Tools und Quellen
Autor:
Prof. Dr. Eva Maria Kiss
Mit Beiträgen von:
M. Sc. Anke Welz
Tools:
- Python: python.org/
- Anaconda: anaconda.com/
- Jupyter Notebook / JupyterLab: jupyter.org/
- Visual Studio Code (VSCode): code.visualstudio.com/
- Spyder: spyder-ide.org/
elab2go-Links
- [1] Datenverwaltung und -Visualisierung mit Pandas: elab2go.de/demo-py2/
- [2] Clusteranalyse mit scikit-learn: elab2go.de/demo-py3/
- [3] Predictive Maintenance mit scikit-learn: elab2go.de/demo-py4/
- [4] Machine Learning mit Keras und Tensorflow: elab2go.de/demo-py5/
Quellen und weiterführende Links
- [1] Offizielle Python Dokumentation bei python.org: docs.python.org/3/tutorial/
sehr umfangreich, Nachschlagewerk, hier findet man Dokumentationen für verschiedene Python-Versionen - [2] Python Tutorial bei Google Developers: developers.google.com/edu/python/introduction
umfangreich, für Fortgeschrittene, verweist auf die offizielle Dokumentation - [3] Python Tutorial bei W3Schools: w3schools.com/python/ – für Einsteiger geeignet, interaktive Ausführung im Browser
- [4] Python Tutorial: evamariakiss.de/tutorial/python/ – Englisch, zum Nachschlagen der wichtigsten Python-Befehle, mit Selbsttest / Quiz
- [5] NumPy: numpy.org/ – Mehrdimensionale Arrays, Mathematische Funktionen, Zufallszahlen
- [6] Matplotlib: matplotlib.org/ – Datenvisualisierung, Plotten
- [7] Pandas: pandas.pydata.org/ – Datenverwaltung, Datenvorbereitung, DataFrames, Series
- [8] Scikit-Learn: scikit-learn.org – Algorithmen für Maschinelles Lernen
- [9] Keras: keras.io – Künstliche Neuronale Netzwerke, Deep Learning